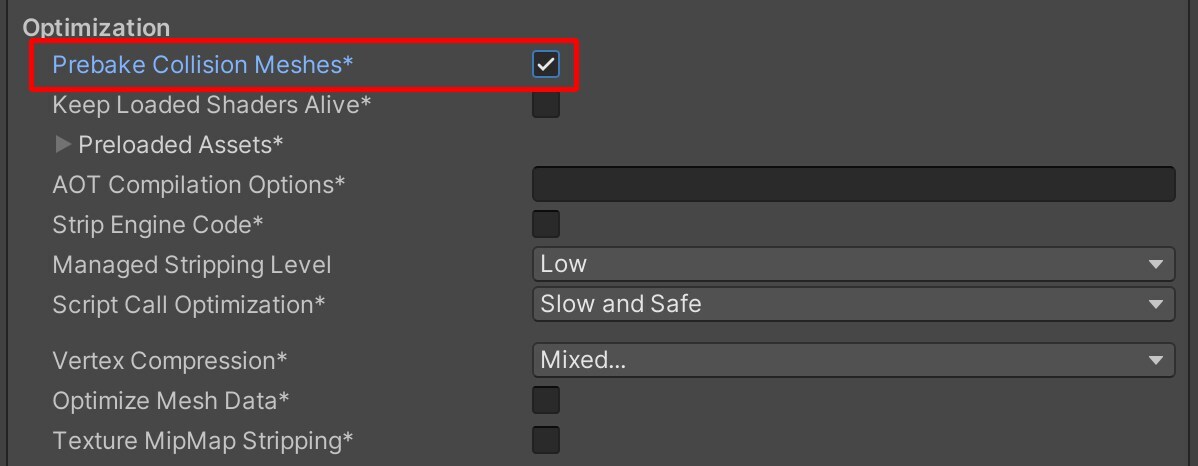
Edit > Project Settings > Audio에서DSP Buffer Size를Best latency로 설정 - Best Performance : 성능이 우선 되어 출력 시 지연이 발생할 수 있음 - Best latency : 지연이 발생하지 않는 것을 우선시하여 출력 품질이 저하될 수 있음
리소스 타입별 세팅
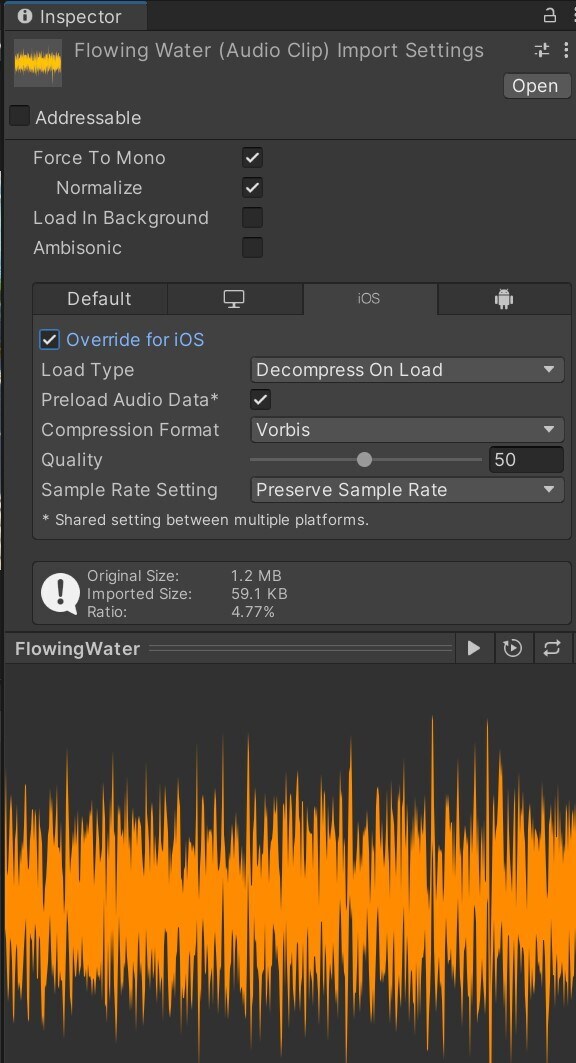
배경음 1 - Force To Mono : 언 체크(퀄리티에 따라 가변) - Load In Background : 체크 - Load Type : Streaming - Preload Audio Data : 언 체크 - Compression Format : Vobis (100%)
배경음 2 - Force To Mono : 언 체크(퀄리티에 따라 가변) - Load In Background : 체크 - Load Type : Compressed In Memory - Preload Audio Data : 언 체크 - Compression Format : Vobis (70%)
효과음 : 작은 크기의 빈번한 출력 - Force To Mono : 체크 - Load In Background : 언 체크 - Load Type : Decompress On Load - Preload Audio Data : 체크 - Compression Format : PCM
긴 효과음(보이스) : 중간 크기의 빈번한 출력 - Force To Mono : 체크 - Load In Background : 언 체크 - Load Type : Compressed In Memory - Preload Audio Data : 체크 - Compression Format : ADPCM
작은 크기의 가끔 발생하는 Sound - Force To Mono : 체크 - Load In Background : 언 체크 - Load Type : Compressed In Memory - Preload Audio Data : 언 체크 - Compression Format : ADPCM
중간 크기의 가끔 발생하는 Sound - Force To Mono : 체크 - Load In Background : 언체크 - Load Type : Compressed In Memory - Preload Audio Data : 언 체크 - Compression Format : Vobis (70%)
개별 리소스 세팅 정보
Force To Mono(모노 강제조정) - 스테레오를 모노로 강제 조정 - 모바일이고 최적화를 중시할 경우 설정(체크) 함
Load In Background(지연된 로딩) - 체크 시 출력 타이밍을 엄격히 지키지 않고, 느긋하게 백그라운드에서 로드 - 따라서 배경음악일 경우 사용 FX 사운드의 경우 체크 해제
Load Type - Decompress On Load 실행과 동시에 압축을 해제 작은 사이즈의 FX 사운드에 유용 많은 메모리 점유 CPU는 적게 사용
- Compressed In Memory 메모리에 압축 상태로 저장, 실행 시 압축을 해제하여 재생 약간의 성능상 오버헤드를 발생시킴 보이스 사운드 등에 사용
- Streaming 저장소에 위치한 오디오를 실시간으로 읽어냄. 보통 배경음악에서 사용
Preload Audio Data - 씬이 로딩될 때 씬에서 사용하는 모든 오디오 클립을 미리 로드 - 언체크시 플레이시 로드 하기에 랙 발생 됨
Compression Format - PCM 최고품질 / 용량 큼 / 작은 파일 크기에 적합 / FX 사운드 Load Type은 Decompress On Load로 하자 즉시 재생해야 하는 매우 짧은 효과음
- ADPCM 중간 품질 / 용량 중간 PCM대비 3.5배의 압축비, 노이즈가 포함됨 총격 소리와 같이 무압축에 가까운 품질 까지는 필요없지만, 지연시간 없이 자주 반복 재생 되야 하는 경우 적절
- Vobis 최저품질 / 용량 적음 / 배경음에 적합 압축률 설정이 가능(보통 70%로 설정) 지연 재생 되어도 무방한 일반적인 배경음
Integrated Success 팀은 유니티 고객들이 복잡한 기술적 문제를 해결할 수 있도록 지원합니다. 유니티의 선임 소프트웨어 엔지니어로 구성된 이 팀과 함께 모바일 게임 최적화에 관한 전문적인 지식을 공유하는 자리를 마련했습니다.
유니티의 엔진 소스 코드를 완벽하게 파악하고 있는Accelerate Solutions팀은 Unity 엔진을 최대한 활용할 수 있도록 수많은 고객을 지원합니다. 팀은 크리에이터 프로젝트를 심도 있게 분석하여 속도, 안정성, 효율성 등을 향상시키기 위해 최적화할 부분을 파악합니다.
모바일 게임 최적화에 관한 인사이트를 공유하기 시작하면서, 원래 계획한 하나의 블로그 포스팅에 담기에는 너무나 방대한 정보가 있다는 사실을 알게 되었습니다. 따라서 이 방대한 지식을 한 권의 전자책(여기에서 다운로드 가능)과 75가지 이상의 실용적인 팁을 담은 블로그 포스팅 시리즈를 통해 제공하기로 했습니다.
이번 시리즈의 두 번째 포스팅에서는 UI, 물리, 오디오 설정을 통해 성능을 개선하는 방법을 자세히 살펴봅니다.이전 포스팅에서는 프로파일링, 메모리, 코드 아키텍처에 대해 다뤘으며, 다음 포스팅에서는 에셋, 프로젝트 구성, 그래픽스에 대해 다룰 예정입니다.
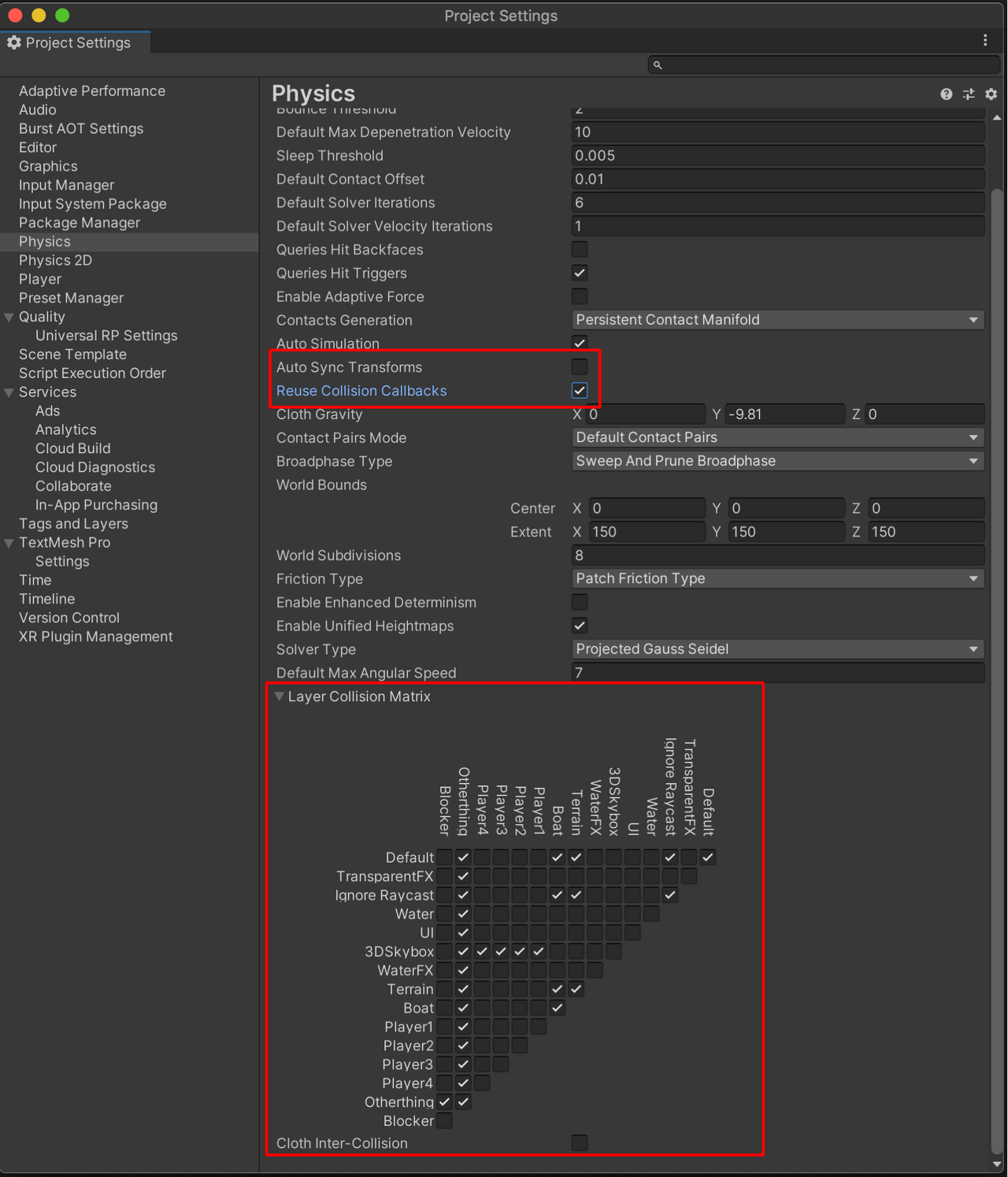
Auto Sync Transforms를 비활성화하고Reuse Collision Callbacks를 활성화합니다.
물리 프로젝트 설정을 수정하여 성능 향상확장
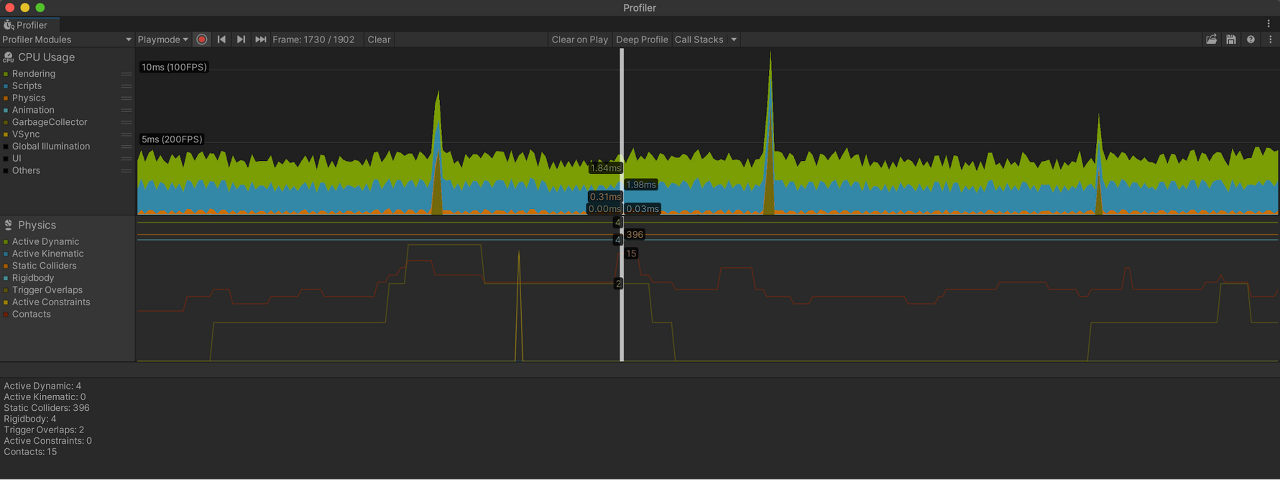
프로파일러의 Physics 모듈을 살펴 성능 문제 확인확장
콜라이더 단순화
메시 콜라이더는 많은 리소스를 요합니다. 복잡한 메시 콜라이더를 기본 또는 단순화된 메시 콜라이더로 대체하여 원래 모양을 대략적으로 표현하세요.
콜라이더에 기본 또는 단순화된 메시 사용확장
물리 메서드를 사용하여 리지드바디 이동
MovePosition또는AddForce와 같은 클래스 메서드를 사용하면Rididbody오브젝트를 이동할 수 있습니다.트랜스폼컴포넌트를 직접 변환하면 물리 월드에서 다시 계산하게 되어, 복잡한 씬의 경우 리소스를 많이 소모합니다.Update대신FixedUpdate에서 물리 바디를 이동시킵니다.
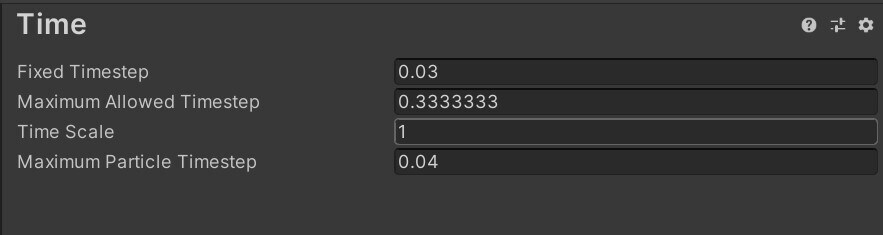
Fixed Timestep 고정
Project Settings에서Fixed Timestep의 기본값은 0.02(50Hz)입니다. 이를 목표 프레임 속도와 일치하도록 변경합니다(예: 30fps는 0.03).
만약 런타임에서 프레임 속도가 하락하면 Unity가 프레임당FixedUpdate를 여러 번 호출하게 되어 물리가 많이 사용된 콘텐츠에서 CPU 성능 문제를 유발할 수 있습니다.
Maximum Allowed Timestep은 프레임 속도가 하락하는 경우 물리 계산 및 FixedUpdate 이벤트가 사용할 수 있는 시간의 양을 제한합니다. 이 값을 낮추면 성능 문제 발생 시 물리 및 애니메이션이 느려지도록 하여 프레임 속도에 미치는 영향을 줄일 수 있습니다.
Fixed Timestep을 목표 프레임 속도와 일치하도록 수정하고 Maximum Allowed Timestep를 낮춰 성능 결함 방지확장
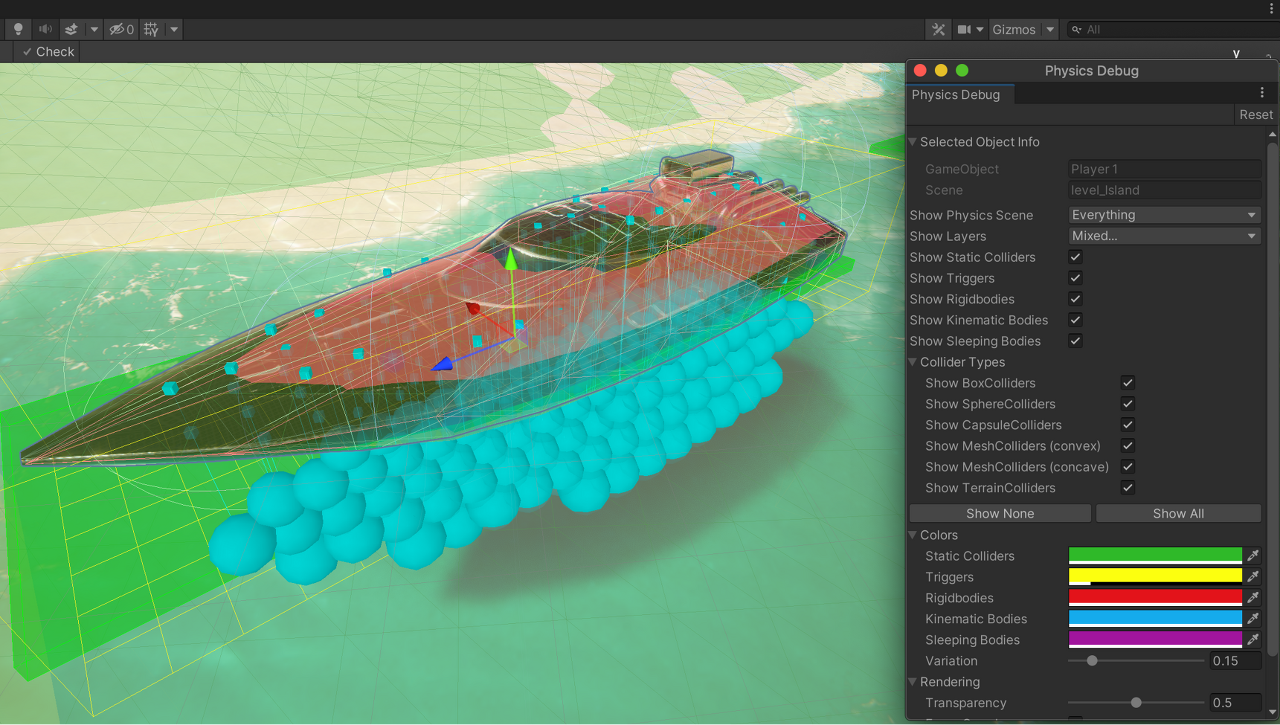
Physics Debugger를 통한 시각화
Physics Debug 창(Windows > Analysis > Physics Debugger)을 사용하면 콜라이더나 불일치로 인한 문제를 해결할 수 있습니다. 이 창은 서로 충돌할 수 있는 게임 오브젝트를 색으로 구별하여 표시합니다.
UGUI(Unity UI)는 성능 문제의 원인이 되는 경우가 많습니다. Canvas 컴포넌트는 UI 요소에 대한 메시를 생성 및 업데이트하고 GPU에 드로우 콜을 보냅니다. 이러한 기능은 리소스를 많이 소모할 수 있으므로 UGUI를 사용할 때 다음 사항을 기억하세요.
Canvas 나누기
수천 개의 요소가 포함된 하나의 대형 Canvas에서는 UI 요소를 하나만 업데이트해도 전체 Canvas가 강제로 업데이트되므로 CPU 스파이크가 발생할 수 있습니다.
다수의 Canvas를 지원하는 UGUI의 기능을 활용하세요. 새로 고침해야 하는 빈도에 따라 UI 요소를 나눕니다. 정적 UI 요소는 별도의 Canvas에 두고, 동시에 업데이트되는 동적 요소는 보다 작은 하위 Canvas에 둡니다.
각 Canvas 내의 모든 UI 요소가 동일한 Z 값, 머티리얼, 텍스처를 갖도록 해야 합니다.
보이지 않는 UI 요소 숨기기
게임에서 간헐적으로만 나타나는 UI 요소(예: 캐릭터가 대미지를 입었을 때 나타나는 체력 표시줄)가 있을 수 있습니다. 보이지 않는 UI 요소가 활성화된 경우에도 드로우 콜을 사용할 수 있습니다. 보이지 않는 UI 컴포넌트를 명시적으로 비활성화하고 필요할 때 다시 활성화합니다.
Canvas의 가시성만 해제하면 되는 경우 게임 오브젝트 대신 Canvas 컴포넌트를 비활성화합니다. 이렇게 하면 메시와 버텍스를 재구성하지 않아도 됩니다.
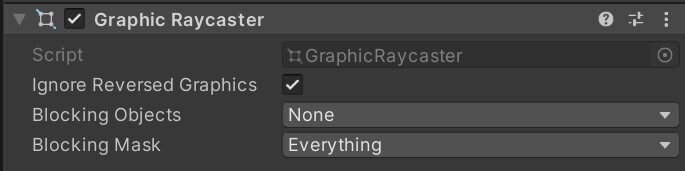
GraphicRaycaster를 제한하고 Raycast Target 비활성화하기
GraphicRaycaster컴포넌트는 화면 터치나 클릭과 같은 입력 이벤트에 필요합니다. 이 컴포넌트는 화면의 각 입력 지점을 순환하며 입력 지점이 UI의 RectTransform 내에 있는지 확인합니다.
계층 구조의 맨 위쪽 Canvas에서 기본GraphicRaycaster를 제거하세요. 대신, 상호 작용이 필요한 개별 요소(버튼, Scrollrect 등)에만GraphicRaycaster를 추가합니다.
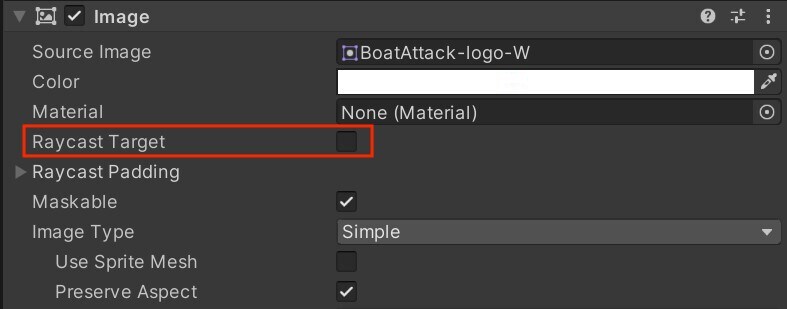
기본적으로 활성화되어 있는 Ignore Reversed Graphics 비활성화확장
아울러 모든 UI 텍스트 및 이미지에서 불필요하게 활성화된Raycast Target도 비활성화합니다. UI에 많은 요소가 있어 복잡한 경우 이와 같이 간단히 설정을 변경하여 불필요한 계산을 줄일 수 있습니다.
가능한 경우 Raycast Target 비활성화확장
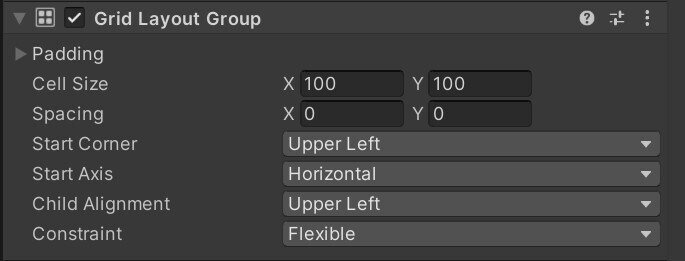
Layout Group
Layout Group은 비효율적으로 업데이트되므로 반드시 필요할 때만 사용하세요. 콘텐츠가 동적이지 않은 경우 Layout Group을 아예 사용하지 말고, 비율 레이아웃에 앵커를 대신 사용하시기 바랍니다. 그 밖의 경우에는 UI 설정을 마친 후 커스텀 코드를 생성하여Layout Group컴포넌트를 비활성화합니다.
동적 요소에 Layout Group(Horizontal, Vertical, Grid)을 사용해야 하는 경우, 중첩되지 않도록 하여 성능을 개선합니다.
중첩된 경우 특히 성능을 하락시키는 Layout Group확장
대형 리스트 뷰와 그리드 뷰 사용 시 주의
대형 리스트 뷰와 그리드 뷰는 많은 리소스를 소모합니다. 대형 리스트 또는 그리드 뷰(예: 수백 개의 항목이 있는 인벤토리 화면)를 만들어야 하는 경우 항목마다 UI 요소를 만드는 대신 소규모 UI 요소의 풀을 재사용하는 것이 좋습니다. 샘플GitHub 프로젝트를 통해 실제 작동 모습을 확인하세요.
요소의 과도한 레이어링 주의
다수의 UI 요소를 레이어링하면(예: 카드 시합 게임에서 쌓여 있는 카드) 오버드로우가 발생합니다. 코드를 커스터마이즈하여 런타임에 레이어링된 요소를 병합하여 요소나 배치(batch)의 수를 줄이세요.
다양한 해상도 및 종횡비 사용
현재 모바일 기기에서 사용 중인 해상도와 화면 크기가 매우 다양하므로, 각 기기에서 최상의 경험을 제공하는대체 버전의 UI를 만드세요.
Integrated Success 팀은 유니티 고객들이 복잡한 기술적 문제를 해결할 수 있도록 지원합니다. 유니티의 선임 소프트웨어 엔지니어로 구성된 이 팀과 함께 모바일 게임 최적화에 관한 전문적인 지식을 공유하는 자리를 마련했습니다.
유니티의 엔진 소스 코드를 완벽하게 파악하고 있는Accelerate Solutions팀은 Unity 엔진을 최대한 활용할 수 있도록 수많은 고객을 지원합니다. 팀은 크리에이터 프로젝트를 심도 있게 분석하여 속도, 안정성, 효율성 등을 향상시키기 위해 최적화할 부분을 파악합니다. 모바일 게임 최적화에 관한 인사이트를 공유하기 시작하면서, 원래 계획한 하나의 블로그 포스팅에 담기에는 너무나 방대한 정보가 있다는 사실을 알게 되었습니다. 따라서 이 방대한 지식을 한 권의 전자책(여기에서 다운로드 가능)과 75가지 이상의 실용적인 팁을 담은 블로그 포스팅 시리즈를 통해 제공하기로 했습니다.
이번 최적화 시리즈 최종 포스팅에서는 에셋, 프로젝트 구성 및 그래픽의 성능을 향상하는 방법을 자세히 살펴봅니다. 이전 포스팅에서는 프로파일링, 메모리, 코드 아키텍처뿐 아니라 물리, UI, 오디오에 대한 팁을 다뤘습니다. 게임 최적화 방법에 관한 시리즈 전체 내용을 확인하고 싶다면 무료 전자책을 다운로드하시기 바랍니다.
프로젝트 구성
모바일 성능에 영향을 줄 수 있는 몇 가지 프로젝트 설정이 있습니다.
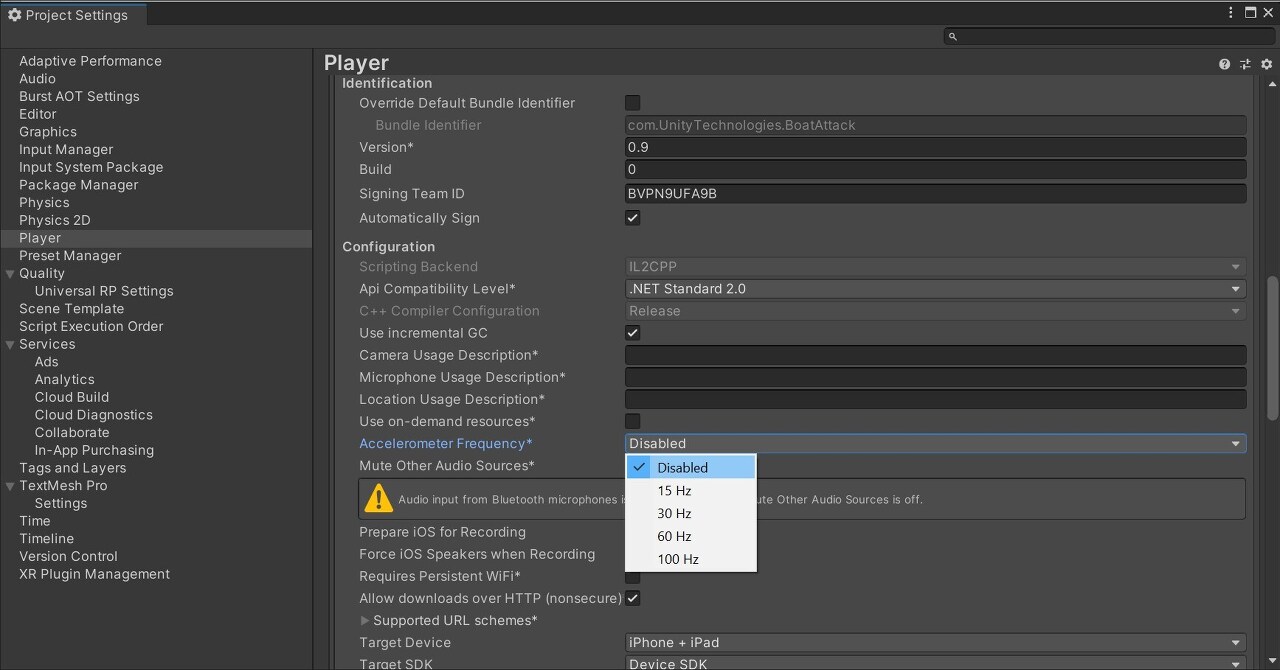
Accelerometer Frequency 감소 또는 비활성화
Unity는 모바일 기기의 가속도 센서를 1초에도 몇 번씩 풀링합니다. 애플리케이션에서 가속도 센서를 사용하지 않는다면 비활성화하거나 빈도를 줄여 성능을 개선하세요.
모바일 게임에서 활용하지 않는다면 Accelerometer Frequency를 비활성화해야 합니다.확장
불필요한 플레이어 설정 또는 품질 설정 비활성화
플레이어설정에서 지원되지 않는 플랫폼의Auto Graphics API를 비활성화하면 셰이더 배리언트가 과도하게 생성되지 않도록 방지할 수 있습니다. 애플리케이션이 오래된 CPU를 지원하지 않는다면 해당 CPU에 대해Target Architectures를 비활성화합니다.
품질설정에서 불필요한 품질 수준을 비활성화합니다.
불필요한 물리 비활성화
게임에서 물리를 사용하지 않는다면Auto Simulation과Auto Sync Transforms를 선택 해제합니다. 해당 기능을 선택하면 별다른 이득 없이 애플리케이션의 속도가 저하될 수 있습니다.
올바른 프레임 속도 선택
모바일 프로젝트에서는 프레임 속도와 배터리 수명, 서멀 스로틀링이 균형을 이루어야 합니다. 기기의 한계인 60fps까지 밀어 붙이기 보다는 30fps 정도에서 타협해 실행하는 것이 좋습니다. Unity는 모바일의 경우 30fps를 기본으로 설정합니다.
또한Application.targetFrameRate를 활용해 런타임 중에 프레임 속도를 동적으로 조정할 수도 있습니다. 예를 들어 속도가 느리거나 비교적 정적인 씬의 경우 30fps 아래로 낮추고 게임플레이 중에는 더 높은 fps 설정을 유지할 수 있습니다.
대규모 계층 구조 사용 지양
Split your hierarchies. 게임 오브젝트가 계층 구조 내에 중첩될 필요가 없다면 부모 자식 관계를 간소화하세요. 계층 구조가 단순하면 씬에서 트랜스폼을 새로고침할 때 멀티스레딩의 이점을 누릴 수 있습니다. 계층 구조가 복잡하면 불필요한 트랜스폼 연산과 높은 가비지 컬렉션 비용이 발생합니다.
모바일 플랫폼은 절반 프레임을 렌더링하지 않습니다. 에디터에서 Vsync를 비활성화하더라도(Project Settings > Quality) 하드웨어 수준에서는 Vsync가 활성화되어 있습니다. GPU가 충분히 빠르게 새로고침할 수 없는 경우, 현재 프레임이 유지되면서 사실상 fps가 줄어듭니다.
에셋
에셋 파이프라인은 애플리케이션의 성능에 지대한 영향을 줄 수 있습니다. 숙련된 테크니컬 아티스트가 에셋 형식, 사양, 임포트 설정을 정의하고 실행하여 프로젝트를 원활하게 진행할 수 있도록 팁을 제공합니다.
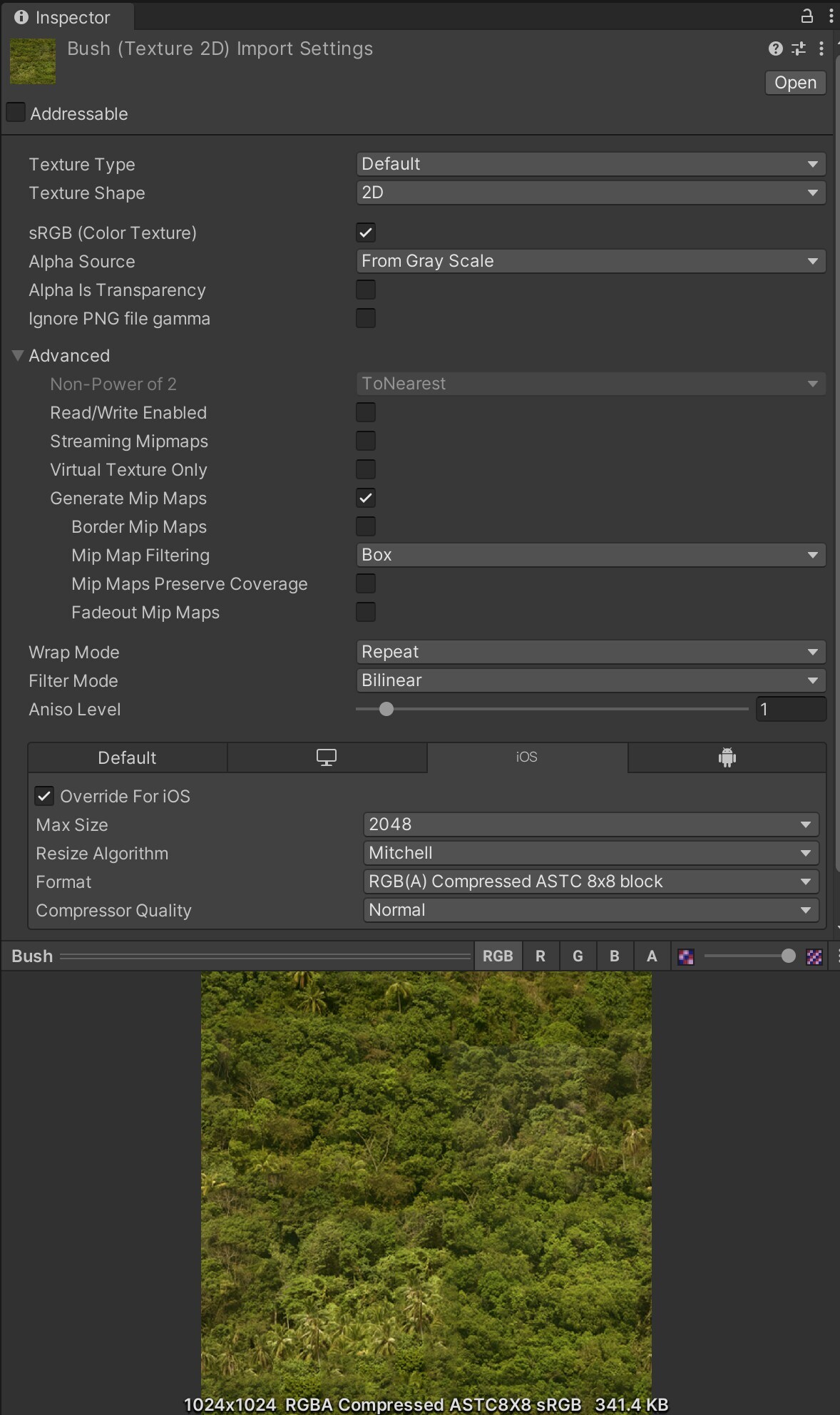
기본 설정에 의존하지 마세요. 플랫폼별 오버라이드 탭을 사용하면 텍스처, 메시 지오메트리와 같은 에셋을 최적화할 수 있습니다. 잘못된 설정으로 인해 빌드 크기가 커지고 빌드 시간이 길어지며 메모리 사용 상황이 열약해질 수 있습니다.프리셋기능으로 특정 프로젝트에 사용할 기본 설정을 커스터마이징하는 것이 좋습니다.
대부분의 메모리가 텍스처에 사용되기 때문에 임포트 설정이 매우 중요합니다. 일반적으로 다음 가이드라인을 따릅니다.
최대 크기 줄이기:시각적으로 허용 가능한 결과를 내는 최소한의 설정을 사용합니다. 이렇게 하면 결과물의 손상을 피하면서 빠르게 텍스처 메모리를 줄일 수 있습니다.
POT(Powers of Two) 사용:Unity에서 모바일 텍스처 압축 형식(PVRCT 또는 ETC)을 사용하려면 POT 텍스처가 필요합니다.
텍스처 아틀라스 사용:하나의 텍스처에 여러 텍스처를 배치하면 드로우 콜을 줄이고 렌더링 속도를 높일 수 있습니다.Unity 스프라이트 아틀라스 또는 타사의 TexturePacker를 사용하여 아틀라스를 만들어 보세요.
Read/Write Enabled 옵션 해제:활성화할 경우 이 옵션은 CPU와 GPU로 처리 가능한 메모리에서 사본을 만들기 때문에 텍스처의 메모리 사용 공간이 중복됩니다. 대부분의 경우 이 옵션은 비활성화 상태로 유지합니다. 런타임에서 텍스처를 생성할 경우Texture2D.Apply함수를 사용하고,makeNoLongerReadable값은true로 전달합니다.
불필요한 밉맵 비활성화:2D 스프라이트와 UI 그래픽처럼 화면상에 일정한 크기로 유지되는 텍스처에는 밉맵이 필요하지 않습니다(카메라의 거리에 따라 다른 3D 모델에 대해서는 밉맵을 활성화된 상태로 유지).
빌드 크기를 최적화하는 데 도움이 되는 적절한 텍스처 임포트 설정확장
텍스처 압축
동일한 모델과 텍스처를 사용하는 두 가지 예를 생각해 보겠습니다. 왼쪽의 설정은 오른쪽에 비해 거의 8배 많은 메모리를 사용하지만 화질에서 큰 차이를 보이지 않습니다.
압축되지 않은 텍스처에는 더 많은 메모리가 필요합니다.확장
iOS와 Android 모두에서 ASTC(Adaptive Scalable Texture Compression)를 사용하세요. 개발 중인 대부분의 게임이 ASTC 압축을 지원하는 최소 사양 기기를 대상으로 합니다.
유일한 예외는 다음과 같습니다.
A7 이하 버전인 기기(예: iPhone 5, 5S)를 대상으로 하는 iOS 게임 - PVRTC 사용
2016년 이전의 기기를 대상으로 하는 Android 게임 -ETC2(Ericsson Texture Compression) 사용
PVRTC와 ETC 같은 압축 형식의 화질이 충분히 높지 않고 ASTC가 대상 플랫폼에서 완전히 지원되지 않는다면 32비트 텍스처 대신 16비트 텍스처를 사용해 보세요.
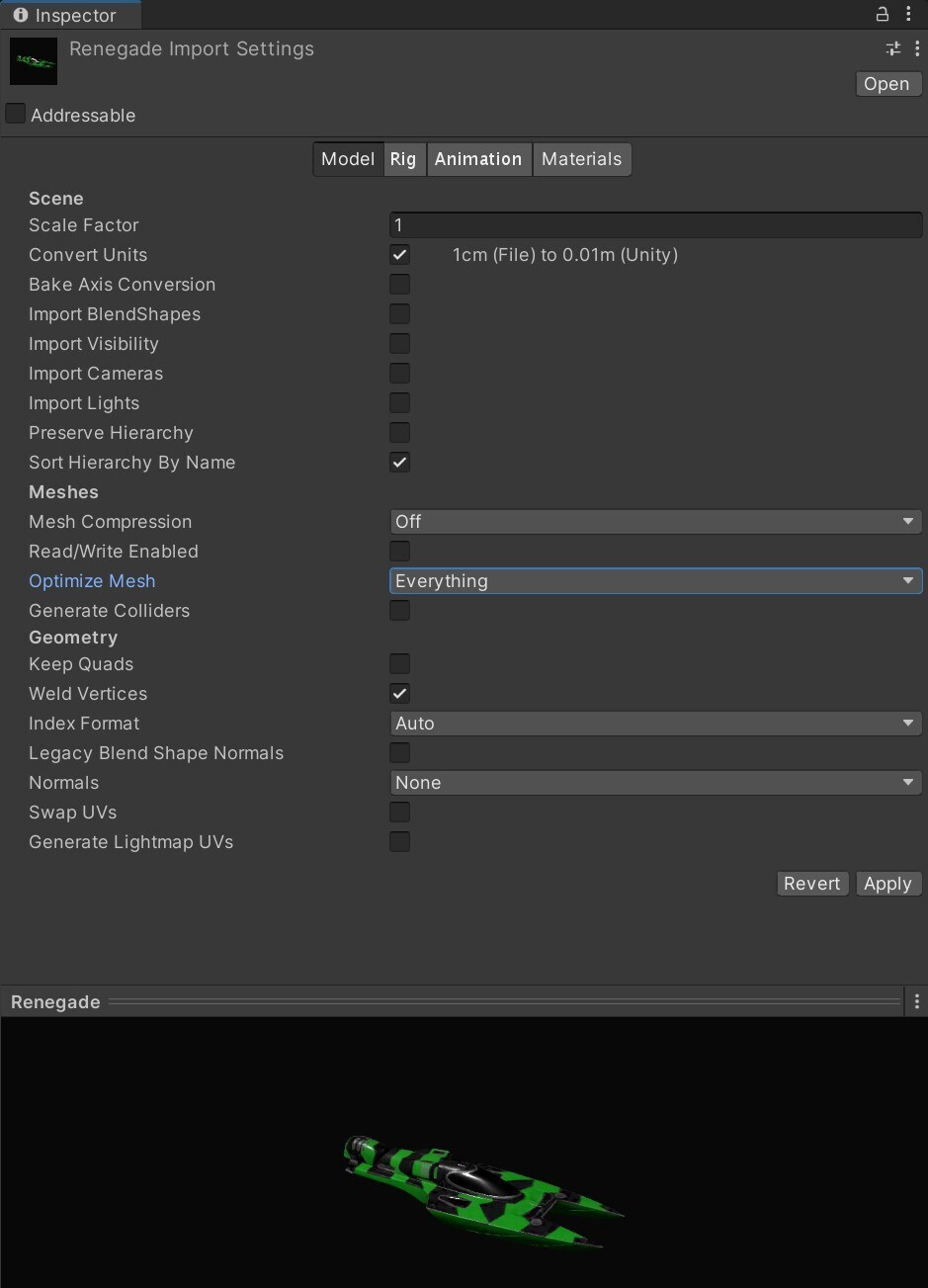
텍스처와 마찬가지로 메시도 신중하게 임포트하지 않으면 과도한 메모리 사용으로 이어질 수 있습니다. 메시의 메모리 사용량을 최소화하려면 다음 지침을 따르세요.
메시 압축:과감한 압축으로 디스크 공간을 줄일 수 있습니다(런타임 시 메모리에는 영향을 주지 않음). 메시 양자화로 인해 정확성이 떨어질 수 있으므로 압축 수준을 다양하게 조절해보고 모델에 적합한 수준을 파악하세요.
Read/Write Enabled 비활성화:이 옵션을 활성화하면 각각 메시 사본이 시스템 메모리와 GPU 메모리에 유지되므로 메모리에서 메시가 중복됩니다. 대부분의 경우에는 비활성화해야 합니다(Unity 2019.2 이하에서는 이 옵션이 기본으로 선택되어 있음).
Rig과 BlendShapes 비활성화:메시에 골격 또는 블렌드 셰이프 애니메이션이 필요하지 않다면 이 옵션을 비활성화합니다.
Normal과 Tangent 비활성화:메시의 머티리얼에 노멀 또는 탄젠트가 필요하지 않은 것이 확실하다면 이 옵션을 선택 해제하여 추가로 메모리를 절감할 수 있습니다.
메시 임포트 설정 확인확장
폴리곤 개수 확인
해상도가 높은 모델은 메모리 사용량이 더 많고 잠재적으로 GPU 시간이 더 길 수 있습니다. 백그라운드 지오메트리에 폴리곤이 50만 개나 필요할까요? DCC에서 모델 수를 줄여 보세요. 카메라의 시점에서 보이지 않는 폴리곤은 삭제하고, 고밀도 메시 대신 텍스처와 노멀 맵을 사용하여 정교한 디테일을 표현하세요.
AssetPostprocessor를 사용하여 임포트 설정 자동화
에셋을 임포트할 때AssetPostprocessor를 사용하여 스크립트를 실행할 수 있습니다. 이렇게 하면 모델, 텍스처, 오디오 등의 임포트 전후로 설정을 커스터마이즈하라는 메시지가 표시됩니다.
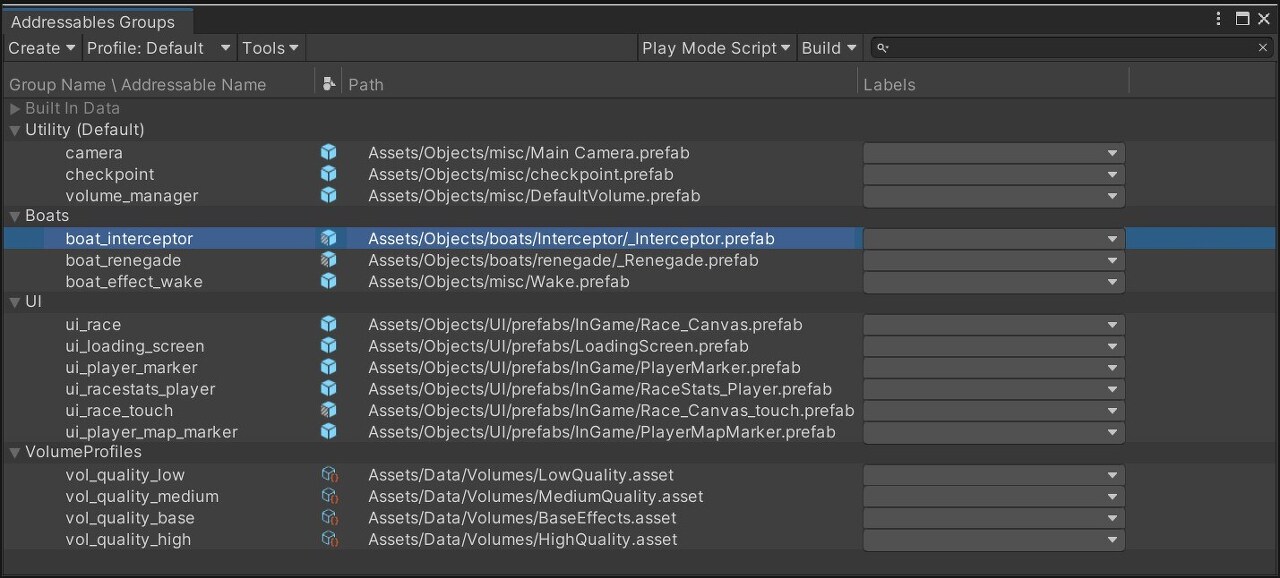
어드레서블 에셋 시스템 사용
어드레서블 에셋 시스템을 사용하면 콘텐츠를 간단하게 관리할 수 있습니다. 이 통합된 시스템은 로컬 경로 또는 원격 콘텐츠 전송 네트워크(CDN)에서 비동기적으로 '주소' 또는 별칭에 따라 AssetBundle을 로드합니다.
확장
코드가 아닌 에셋(모델, 텍스처, 프리팹, 오디오, 전체 씬)을AssetBundle에 나눌 경우 다운로드 가능한 콘텐츠(DLC)로 분리할 수 있습니다.
그런 다음 어드레서블을 사용하여 모바일 애플리케이션에 사용할 더 작은 초기 빌드를 만듭니다.클라우드 콘텐츠 전송을 사용하면 게임 콘텐츠를 호스트하고 게임이 진행됨에 따라 플레이어에게 데이터를 전송할 수 있습니다.
어드레서블 에셋 시스템을 사용하여 '주소'에 따라 에셋 로드확장
여기를 클릭하여 어드레서블 에셋 시스템이 에셋 관리의 번거로움을 덜어주는 방법에 대해 알아보세요.
그래픽스 및 GPU 최적화
Unity는 프레임마다 렌더링해야 하는 오브젝트를 지정한 다음 드로우 콜을 만듭니다. 드로우 콜은 오브젝트(예: 삼각형)를 그리기 위한 그래픽스 API 호출이며, 배치는 함께 실행되는 드로우 콜의 그룹입니다.
프로젝트가 복잡해질수록 GPU의 워크로드를 최적화해 주는 파이프라인이 필요합니다.URP(Universal Render Pipeline, 유니버설 렌더 파이프라인)는 현재 싱글 패스 포워드 렌더러를 사용하여 모바일 플랫폼에서 고화질 그래픽을 구현합니다(디퍼드 렌더링은 향후 릴리즈에서 제공될 예정). 콘솔과 PC에서의 동일한 물리 기반 광원 및 머티리얼도 스마트폰이나 태블릿으로 확장할 수 있습니다.
다음 가이드라인은 그래픽의 속도를 높이는 데 도움이 될 수 있습니다.
드로우 콜 배칭
함께 그릴 오브젝트를 배치로 구성하면 각 오브젝트를 그리는 데 필요한 상태 변화가 최소화됩니다. 그 결과 오브젝트를 렌더링하는 데 드는 CPU 비용이 감소하므로 성능이 향상됩니다. Unity는 여러 기법을 사용하여 여러 오브젝트를 보다 적은 수의 배치로 구성할 수 있습니다.
동적 배칭:작은 메시의 경우 Unity는 CPU에서 버텍스를 그룹화하고 변환한 다음 모두를 한 번에 그립니다. 참고: 로우 폴리 메시가 충분한 경우에만 이 기법을 사용하세요(버텍스 속성 900개, 버텍스 300개 미만). Dynamic Batcher는 이보다 큰 메시를 배칭하지 않으므로, 용도에 맞지 않게 활성화할 경우 프레임마다 배칭할 작은 메시를 찾느라 CPU 시간을 낭비하게 됩니다.
정적 배칭:움직이지 않는 지오메트리의 경우 Unity는 동일한 머티리얼을 공유하는 메시에 대한 드로우 콜을 줄일 수 있습니다. 동적 배칭에 비해 더 효율적이지만 메모리 사용량은 늘어납니다.
GPU 인스턴싱:동일한 오브젝트의 수가 많을 때 이 기법을 사용하면 그래픽 하드웨어의 사용을 통해 더 효율적인 배칭이 가능합니다.
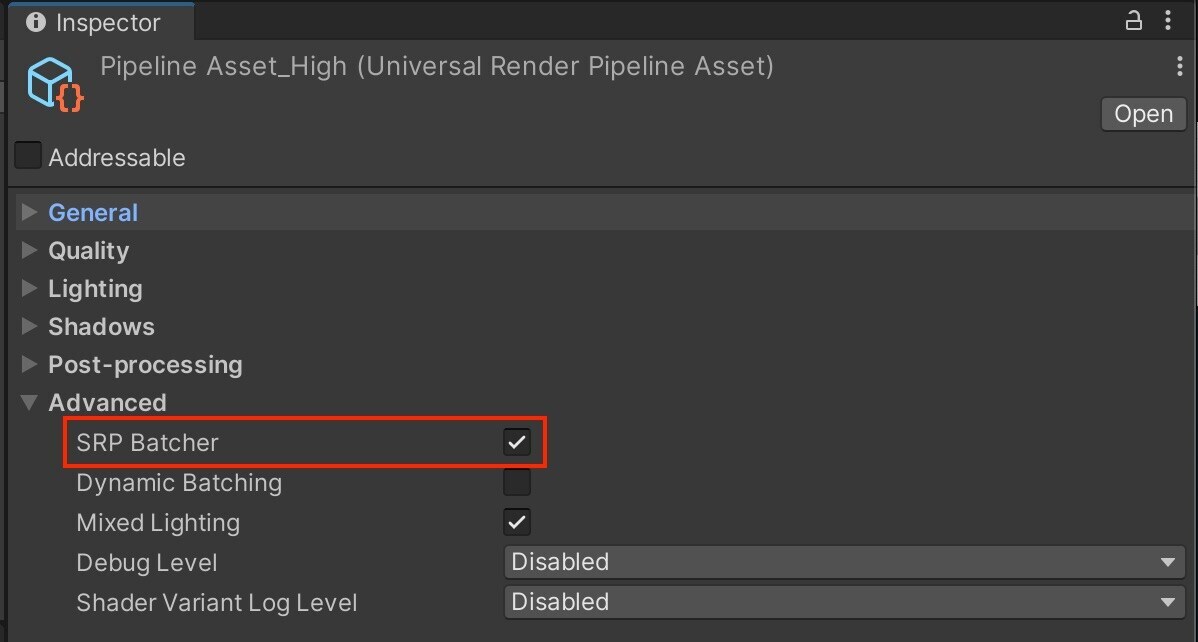
SRP 배칭:유니버설 렌더 파이프라인 에셋의Advanced항목에서SRP Batcher를 활성화합니다. 이렇게 하면 씬에 따라 CPU 렌더링 시간이 크게 빨라집니다.
이와 같은 배칭 기법을 활용할 수 있도록 게임 오브젝트를 정리하세요.확장
프레임 디버거 사용
프레임 디버거는 개별 드로우 콜에서 각 프레임이 구성된 방식을 보여줍니다. 게임이 렌더링되는 방식을 분석하는 데 도움이 되는 셰이더 속성의 문제 해결에 유용한 도구입니다.
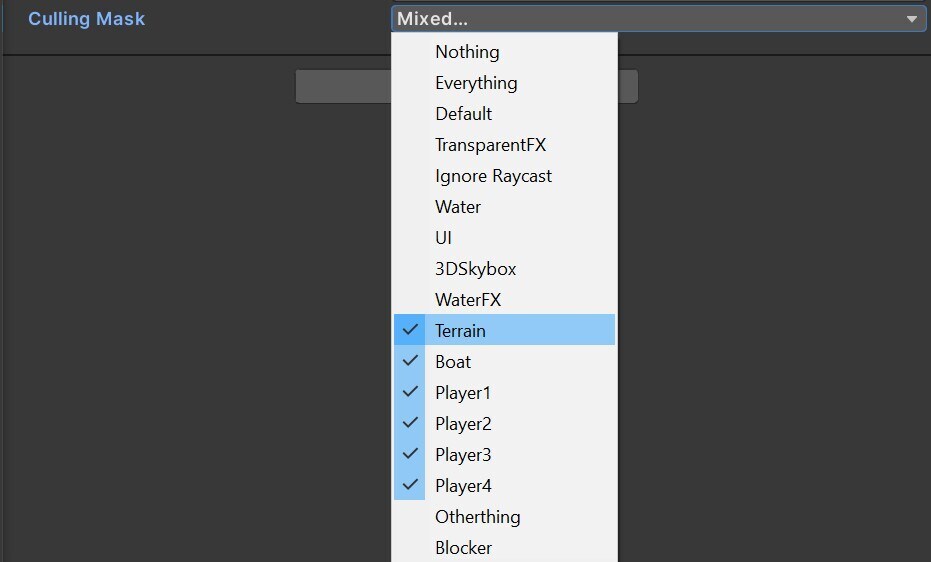
광원이 여러 개인 복잡한 씬의 경우 레이어를 사용해 오브젝트를 분리한 다음 각 광원의 영향을 특정 컬링 마스크로 한정합니다.
레이어를 사용하여 광원의 영향을 특정 컬링 마스크로 제한하기확장
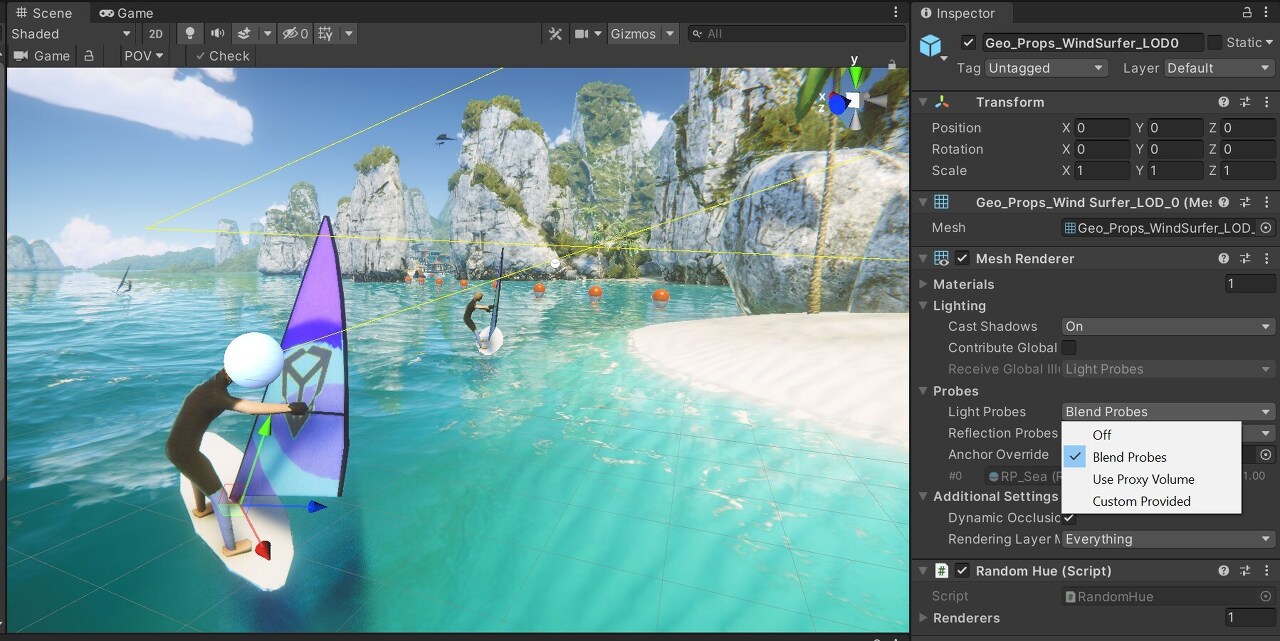
움직이는 오브젝트에 라이트 프로브 사용
라이트 프로브는 씬 내의 빈 공간에 대해 베이크된 조명 정보를 저장하고 직접 또는 간접적으로 고품질 조명을 제공합니다. 여기에는 동적 광원에 비해 매우 빠르게 계산하는 구면 조화(Spherical Harmonics) 함수가 사용됩니다.
백그라운드의 동적 오브젝트를 비추는 라이트 프로브확장
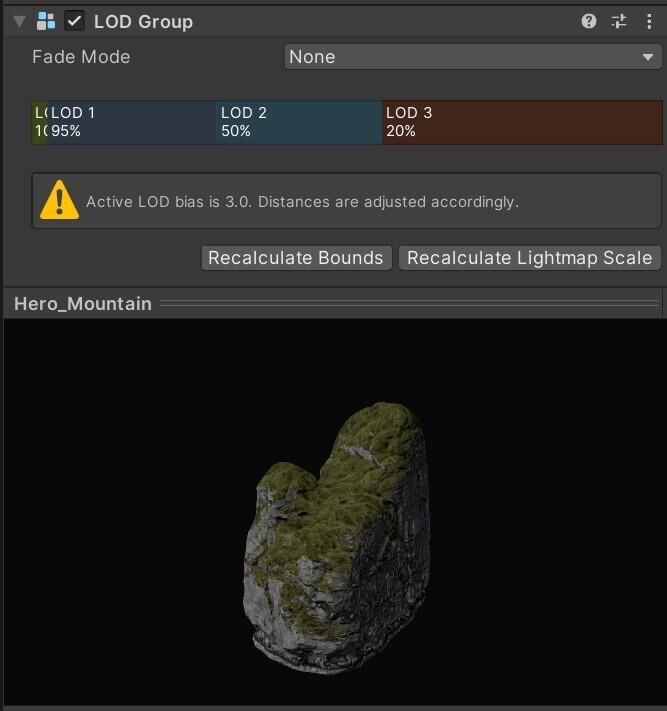
디테일 수준(LOD) 사용
오브젝트가 멀리 이동하면디테일 수준을 통해 단순한 메시와 머티리얼, 셰이더를 사용하도록 조정하거나 전환하여 GPU 성능을 보조할 수 있습니다.
LOD 그룹을 사용하는 메시의 예시확장
다양한 해상도로 모델링한 소스 메시확장
오클루전 컬링을 사용하여 숨겨진 오브젝트 제거
다른 오브젝트 뒤에 숨겨진 오브젝트는 계속 렌더링되며 리소스 비용을 발생시킬 수 있습니다. 오클루전 컬링을 사용하여 이러한 오브젝트를 폐기하세요.
카메라 뷰 바깥의 절두체 컬링은 자동인 반면 오클루전 컬링은 베이크된 과정입니다. 오브젝트를Static Occluders또는Occludees로 표시한 다음Window > Rendering > Occlusion Culling을 통해 베이크하면 됩니다. 모든 씬에 필요하지는 않지만 많은 경우에 컬링으로 성능을 향상할 수 있습니다.
스마트폰과 태블릿이 점점 발전함에 따라 새로 출시되는 기기일수록 매우 높은 해상도를 자랑하곤 합니다.
Screen.SetResolution(width, height, false)을 사용하여 출력 해상도를 낮추면 어느 정도의 성능을 다시 확보할 수 있습니다. 여러 해상도를 프로파일링하여 화질과 속도 사이에서 최적의 균형을 찾아보세요.
카메라 사용 제한
모든 카메라는 작업 수행에 어느 정도의 오버헤드를 유발합니다. 렌더링에 필요한 카메라 컴포넌트만 사용하세요. 저사양 모바일 플랫폼에서는 카메라당 최대 1ms의 CPU 시간을 사용할 수 있습니다.
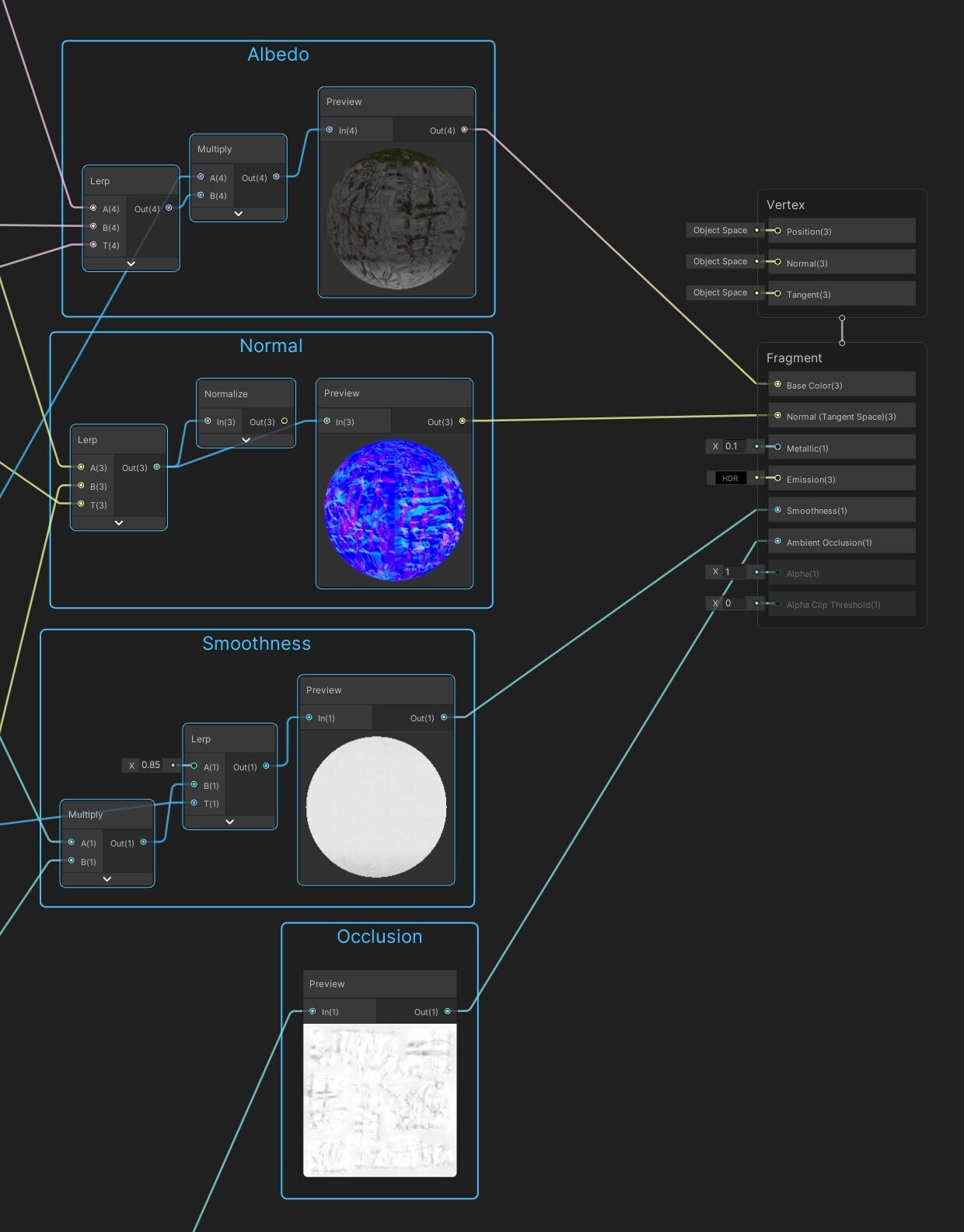
셰이더를 단순하게 유지
유니버설 렌더 파이프라인은 이미 모바일 플랫폼에 최적화된 경량 릿 셰이더와 언릿 셰이더를 다양하게 포함하고 있습니다. 런타임 메모리 사용량에 상당한 효과를 미칠 수 있으므로 셰이더 베리에이션을 최대한 낮게 유지하세요. 기본 URP 셰이더가 필요에 맞지 않는다면 셰이더 그래프를 사용해 머티리얼의 외관을 커스터마이징할 수 있습니다.여기에서 셰이더 그래프를 사용해 시각적으로 셰이더를 빌드하는 방법을 알아보세요.
셰이더 그래프로 커스텀 셰이더 만들기확장
오버드로우와 알파 블렌딩의 최소화
불필요한 투명 또는 반투명 이미지를 그리지 마세요. 모바일 플랫폼은 오버드로우와 알파 블렌딩의 영향을 크게 받습니다. 거의 보이지 않는 이미지 또는 이펙트를 겹치지 마세요.RenderDoc그래픽 디버거를 사용해 오버드로우를 확인할 수 있습니다.
포스트 프로세싱 이펙트 제한
글로우와 같은 전체 화면포스트 프로세싱이펙트는 성능을 크게 떨어뜨릴 수 있습니다. 프로젝트의 아트 방향성에 따라 주의하여 사용하세요.
모바일 애플리케이션에서는 포스트 프로세싱 이펙트를 단순하게 유지확장
Renderer.material 유의하기
스크립트의Renderer.material에 액세스하면 머티리얼이 복사되고 새로운 사본에 대한 참조가 반환됩니다. 이로 인해 이미 해당 머티리얼을 포함하는 기존 배치가 손상됩니다. 배칭된 오브젝트의 머티리얼에 액세스하려면Renderer.sharedMaterial을 대신 사용하세요.
SkinnedMeshRenderers 최적화
스킨드 메시를 렌더링하는 데는 비용이 많이 듭니다.SkinnedMeshRenderer를 사용하는 모든 오브젝트에 사용할 필요가 있는지 확인하세요. 게임 오브젝트에 가끔 애니메이션만 필요한 경우BakeMesh함수를 사용하여 스킨드 메시를 정적인 포즈로 고정하고 런타임 시에는 더 단순한MeshRenderer로 대체하세요.
반사 프로브 최소화
반사 프로브는 사실적인 반사를 만들어 낼 수 있지만 배치의 차원에서 봤을 때 비용이 매우 높습니다. 저해상도 큐브맵, 컬링 마스크, 텍스처 압축을 사용해 런타임 성능을 높이세요.
모바일 성능 최적화에 대한 전체 가이드 다운로드
이 포스팅은 모바일 성능 최적화 시리즈의 마지막 게시물이며, 팀에서 제공하는 유용한 팁의 전체 목록을 확인하고자 하는 분들을 위해 52페이지 분량의 전자책을 출간하였으며,여기에서 다운로드 할 수 있습니다.