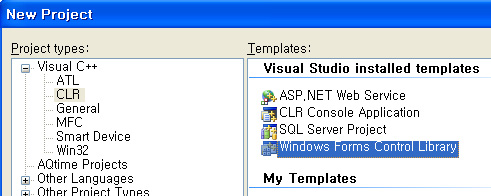
최근에 구글에서 MS의 IE(Internet Explorer)를 의식한 새로운 웹브라우저인 Chrome(크롬) 베타를 공개해습니다. 구글답게 오픈소스이고 소스코드를 보면 구글 엔지니어들의 코딩 스타일을 알 수가 있었습니다.
구글에서는 코드의 가독성과 효율적인 유지보수를 위하여 모두 코딩 스타일 가이드가 정해져 있습니다.
사실 구글뿐만 아니라 우리가 좀 알만한 소프트웨어 패키지를 개발하는 개발사들은 내부적으로 자신들만의 코딩 스타일 가이드가 있을 거라 생각됩니다.
조엘온 소프트웨어 블로그에서는 "모드 개발사가 각각 코딩스타일을 갖을 필요 없이 컴파일러 자체에서 문법처럼 정해서 어긋나면 Error 처리 할것" 즉, 전세계 공통 코딩 스타일이 통일 되도록 만들어야 한다는 주장이 있습니다. 사실 이렇게 되면 나름 장점도 있지만 개인적인 코딩 성향을 무시해버리는 처사가 아닐까도 생각됩니다. 하지만 코딩 스타일은 무조건 보기 좋게 하려고 하기 위한것 보다 왜 그렇게 해야만하는지 타당한 이유들이 있습니다. 구글의 코딩스타일은 Effective C++ 과 More Effective C++ 을 그대로 옮겨놓은듯한 느낌이 나는군요 !! 그만큼 C++언어를 사용하면서 주의해야할 것들을 코딩스타일로 미연에 방지하고자 하는 의도도 옅보이네여.
그럼 구글 엔지니어들의 코딩 스타일을 보겠습니다.
원문은 http://google-styleguide.googlecode.com/svn/trunk/cppguide.xml 입니다.
배경
C++은 구글의 많은 오픈소스 프로젝트에 사용되어지는 메인 개발 언어이다.
모든 C++ 프로그래머가 알고 있듯이 C++은 아주 많은 강력한 특징들을 갖고있으나 이 강력함이 언어를 상당히 복잡하게 만든다. 따라서 더 많은 버그를 발생하고 코드를 읽기 어렵고 유지보수하기 힘들게 만든다.
이 가이드의 목적은 C++을 사용하면서 해야할것과 해야하지 말아야할 것들을 자세히 알려 줌으로써 C++언어만의 복잡성을 관리하기위한 것이다. 코더들은 이런 규칙을 통해 C++ 언어의 특징들을 생산적으로 사용할 수 있다.
스타일은 우리의 C++코드를 관리(적용)하는 관습(관례)라고 부르는 것이다.
스타일이란 용어는 약간 잘못 사용된 용어이다, 왜냐하면 이런 관습(관례)들은 단순히 소스파일 형식보다 더많은 것들을 다루고 있기 때문이다.
우리가 코드기반을 다루기 쉽도록 유지하는 한 방법은 코드를 일관성있게 작성하도록 하는 것이다. 어떤 프로그래머던 다른사람의 코드를 볼수있고 빠르게 이해할 수 있도록 코드를 작성하는 것은 매우 중요하다. 통일된 스타일을 유지하고 관례들을 따른다는 것은 코딩에 숨겨진 다양한 의미들을 추론하기 위하여 "pattern-matching"을 좀더 쉽게 사용할수 있다는것을 의미한다.
우리가 코드기반을 다루기 쉽도록 유지하는 한 방법은 코드를 일관성있게 작성하도록 하는 것이다.
어떤 프로그래머던 다른사람의 코드를 볼수있고 빠르게 이해할 수 있도록 코드를 작성하는 것은 매우 중요하다. 통일된 스타일을 유지하고 관례들을 따른다는 것은 코딩에 숨겨진 다양한 의미들을 추론하기 위하여 "pattern-matching"을 좀더 쉽게 사용할수 있다는것을 의미한다.
개발에서 일반적으로 요구되어지는 관용구(idioms)나 패턴(patterns) 들은 코드를 훨씬더 이해하기 쉽게 만든다. 몇몇 경우에서 특정 스타일의 규칙들을 변경할만한 좋은 논쟁거리가 있을수있다. 하지만 우리는 일관성을 유지하기위하여 스타일 규칙을 따를 것이다.
이 가이드에서 다른 이슈는 C++의 거대함이다.
C++은 많은 고급적인 문법들을 가진 거대한 언어이다.
우리는 몇몇경우에서 특정한 문법들의 사용을 강요하거나 또는 심지어 사용하지 못하도록 할것이다. 우리가 이렇게 하는것은 코드를 단순하게 유지하고 이런 문법들을 사용함으로써 발생될 수 있는 일반적인 다양한 오류와 문제들을 피하기 위해서이다.
이 가이드에서는 이런 문법들을 리스트했고 왜 그것들의 사용을 제한하는지를 설명한다.
구글에 의해 개발되어진 오픈 소스 프로젝트는 이 가드의 요구사항을 따른다.
이 가이드� C++ 튜토리얼이 아님을 명심해라. 우린 독자가 C++언어를 어느정도 알고있다고 가정했다.
Header Files
단위테스트(unittests)와 단지 main() 함수만 있는 .cpp 파일을 제외하고
일반적으로 모든 .cpp 파일은 .h 파일과 쌍으로 연관되어 있다.
헤더파일의 올바른 사용은 여러분의 코드의 가독성과, 크기 그리고 성능향상에 큰 차이점을 만들 수가 있다. 아래 규칙들은 헤더파일을 올바르게 사용하기 위한 다양한 지침이다.
The #define Guard
모든 헤더 파일은 다중 포함을 방지하기 위해 #define 가드를 가진다.
심벌명의 형식은 ___H_ 해야 한다.
심벌명의 유일성을 보장하기위해서 프로젝트 소스트리의 완전 경로에 기반해야한다.
예를 들어 foo 라는 프로젝트에 foo/src/bar/baz.h 파일인경우 아래 처럼 할 수 있다.
#ifndef FOO_BAR_BAZ_H_
#define FOO_BAR_BAZ_H_
...
#endif // FOO_BAR_BAZ_H_
Header File Dependencies
당신이 .h파일에 #include 를이용하여 다른 .h파일을 인클루드하면 그 파일이 변경될때마다 코드를 다시 컴파일 해야만 할 것이다. 그러므로 우리는 헤더파일안에 다른 헤더파일들을 인클루드하는것을 최소화하는게 더 낮다. 당신은 전방선언을 사용함으로써 헤더파일안에 요구되어지는 다른 헤더파일들의 포함을
최소화 할 수 있다. 만약 당신의 헤더파일이 File클래스의 선언에 접근하지 않는 방법으로 File 클래스를 사용한다면 #include "file/base/file.h" 대신에 class File; 를 사용할 수 있다.
클래스 정의에 대한 접근없이 헤더파일 안에서 클래스 Foo를 사용하는 방법은 다음과 같다.
*Foo* 또는 Foo& 즉 클래스 포인터나 참조자를 선언한다.
*Foo 타입의 리턴 값이나 인자를 가진 함수를 선언(정의가 아닌)할 수 있다.
*Foo 타입의 static 데이터 멤버를 선언할 수 있다. static데이터 멤버는 클래스 정의 밖에서 정의 되어지기 때문이다.
한편 당신의 클래스가 Foo에 대한 서브클래스이거나 Foo타입의 데이터 멤버를 갖는다면 Foo에 대한 헤더파일을 인클루드해야만 한다.
때때로 객체멤버 대신 포인터멤버(scoped_ptr를 사용하면 더 좋다)를 이용하는것이 더 좋다. 그러나 이것은 코드 가독성을 복잡하게 하고 성능비용을 지불해야한다. 그래서 헤더파일안에 인클루드하는것을 최소하하기 위한것이 유일한 목적이면 이런 변환은 피해라.
물론 .cc 파일들도 전형적으로 그들이 사용하는 클래스의 정의를 요구하고 보통은 몇몇 헤더파일들을 포함해야만 한다.
Inline Functions
10라인 이하의 아주 작은 함수일때만 인라인 함수를 정의해라.
정의 : 보통의 함수 호출 메카니즘을 통해 함수를 호출하는것보다는 컴파일러가 함수를 인라인으로 학장하는 방법으로 함수를 선언 할 수 있다.
장점 : 인라인닝된 함수는 인라인된 함수가 작은한 더 효과적인 오브젝트 코드를 생성할수있다.
단점 : 인라인닝의 과도 사용은 프로그램을 더 느리게 만들 수 있다.
인라인닝하는 것은 함수의 사이즈에 의존적으로 코드 크기를 크게하거나 작거 만들어 질수 있다.
매우 작은 함수를 인라인닝하는것은 보통 코드 크기를 감소시킬 수 있지만 매우 큰 함수를 인라이닝하는것은 코드 크기를 극적으로 크게 만든다. 요즘 프로세서에서 더 작은 코드는 더 낳은 인스트럭션 캐시(instruction cache)를사용하기 때문에 보통 더 빠르게 실행된다.
결론 : A decent rule of thumb (경험상) 10라인 이상인 함수는 인라인하지 않는 것이좋다. 그리고 loop나 switch 문장이 들어간 함수는 인라인은 효과적이지 않다. 그리고 가상또는 재귀함수는 일반적으로 인라인되지 않는다는것을 알고있어야 한다. 보통 재귀 함수들을 인라인되지 않아야 한다.
The -inl.h Files
당신은 복잡한 인라인 함수들을 정의할 필요가 있을때 파일명뒤에 -inl.h 를 사용해라.
Function Parameter Ordering
함수를 정의할때 파라미터 순서는 입력 -> 출력 순으로 한다.
C/C++ 함수들의 파라미터들은 입력만 있는경우, 출력만있는 경우 그리고 둘다 있는 경우가 있다.
입력 파라미터들을 보통 값 또는 const 참조자들인 반면 출력그리고 입/출력 파라미터들을 non-const 포인터일 것이다. 함수 정의시 파라미터 순서는 출력 파라미터 전에 모든 입력 파라미터를 놓아라.
이것은 엄한 규칙(hard-and-fast rule)이 아니다. 출력과 입력둘다 있는 파라미터(클래스나 구조체)들은 아마도 연관된 함수의 일관성을따라 위 규칙을 알맞게 바꿀( bend the rule) 필요가 있을것이다.
Names and Order of Includes
숨겨진 의존성을 피하고 가독성을 위하여 C 라이브러리, C++라이브러리, 기타 다른 라이브러리, 그리고 사용자 정의 라이브러리및 파일(.h)순으로 인클루드(include)해라. 프로젝트의 모든 헤더파일들은 UNIX 디렉토리 쇼트컷(shortcuts : (. : 현재 디렉토리 ) 또는 ( .. : 부모 디렉토리 ) ) 사용없이 프로젝트 소스 디렉토리 구조로 인클루드되어야 한다.
예를 들어 google-awesome-project/src/base/logging.h 는
#include "base/logging.h" 처럼 인클루드해야한다. ( ./ or ../ 를 사용하지 말라는것)
dir/foo.c의 주 목적이 dir2/foo2.h 의 기능을 구현하거나 테스트하기 위한 경우 아래처럼 인클루드 순서를 정해라.
dir2/foo2.h (preferred location — see details below).
C system files.
C++ system files.
Other libraries' .h files.
Your project's .h files.
이 순서대로하면 숨겨진 의존성들을 줄일수 있다. 우리는 스스로 컴파일되어지기 위한
모든 헤더파일을 원한다. 이것을 성취하기위한 가장 쉬운 방법은 abc.c 안에 처음으로 abc.h 파일을 인클루드 하도록 하는것이다. 그리고 알파벳 순으로 인클루드 해라.
예를들어 google-awesome-project/src/foo/internal/fooserver.cc 는 아래처럼 인클루드 될 것이다.
#include "foo/public/fooserver.h" // Preferred location.- fooserver.cc 의 헤더파일
#include // C 라이브러리 헤더파일
#include // C 라이브러리 헤더파일
#include // C++ 라이브러리 헤더파일
#include // C++ 라이브러리 헤더파일
#include "base/basictypes.h" // 프로젝트파일인데 알파벳 순으로...
#include "base/commandlineflags.h"
#include "foo/public/bar.h"
Scoping
Namespaces
.cc 파일에 이름없는 네임스페이스를 사용해라. 네임스페이스의 이름은 프로젝트에 기반하거나 프로젝트 패스로 선택할 수 있다.. using 연산자를 사용하지 말아라.
정의 : 이름공간(Namespace)은 개체를 구분할 수 있는 범위를 나타내는 말로 일반적으로
네임스페이스는 전역공간에서 이름 충돌을 하지 못하도록 하는데 유용하다.
장점 : 네임스페이스는 (계층적) axis of naming 을 제공하고 또한 (계층적)name axis 는 클래스들에 의해 제공되어진다. 예를들어 만약 두개의 다른 프로젝트의 전역 공간에 클래스 Foo를 가진다면 이 Foo 라는 심벌은 런타임 또는 컴파일타임시 충돌 될 수있다. 만약 각 프로젝트에 project1::Foo 나 project2::Foo 네임스페이스를 사용하면 충돌을 방지 할 수 있다.
단점 : 네임스페이스들은는 (계층적) axis of naming 을 제공하고 또한 (계층적)name axis 는 클래스들에 의해 제공되어지기때문에 헷갈릴 수 있다. 헤더파일 안에 이름없는 스페이스(unnamed spaces ) 사용은 C++ One Definition Rule (ODR)의 위반을 쉽게 야기 할 수 있다.(.소스파일에서만 사용할것)
결론 : 아래 방법대로 네임스페이스를 사용해라.
Unnamed Namespaces
이름없는 네임스페이스는 런타임 이름 충돌들을 피하기위해서 .cc파일에 사용할 수 있고 사용하기를 바란다.
namespace { // This is in a .cc file.
// The content of a namespace is not indented
enum { UNUSED, EOF, ERROR }; // Commonly used tokens.
bool AtEof() { return pos_ == EOF; } // Uses our namespace's EOF.
} // namespace
그러나, 특별한 클래스와 연관된 파일범위(file-scope) 선언은 이름없는 네임스페이스의 멤버로서 보다 타입, 정적 데이터 멤버, 또는 정적 멤버 함수로서 클래스안에 선언되어질 수 있다. 이름없는 네임스페이스 끝에 // namespace 주석을 써라.
.h 헤더파일에서는 이름없는 네임스페이스를 사용하지 말아라.
Named Namespaces
이름있는 네임스페이스는 아래처럼 사용해라.
네임스페이스는 인클루드 헤더파일 ,gflags 정의/선언, 그리고 클래스 전방선언 후에 전체 소스파일을 감싸라.
// In the .h file
namespace mynamespace {
// All declarations are within the namespace scope.
// Notice the lack of indentation.
class MyClass {
public:
...
void Foo();
};
} // namespace mynamespace
// In the .cc file
namespace mynamespace {
// Definition of functions is within scope of the namespace.
void MyClass::Foo() {
...
}
} // namespace mynamespace
일반적으로 .cc 파일에서 다른 네임스페이스안에 참조클래스가 포함되어 더 복잡 할 수 있다.
#include "a.h"
DEFINE_bool(someflag, false, "dummy flag");
class C; // Forward declaration of class C in the global namespace.
namespace a { class A; } // Forward declaration of a::A.
namespace b {
...code for b... // Code goes against the left margin.
} // namespace b
*네임스페이스 std 의 어떤것도 선언하지 말아라. 심지어 표준 라이브러리 클래스의 전방선언도 하지 말아라. 네임스페이스 std안의 엔티티들을 선언하는것은 정의되어있지 않은 행위, 즉 이식성이 없다.
표준라이브러리부터 엔티티를 선언하기위해 적절한 헤더파일을 포함해라.
*using 연산자를 사용하지 말것
// Forbidden -- This pollutes the namespace.
using namespace foo;
*.cc 파일, 함수, 메서드, .h파일의 메서드또는 클래스들에서는 using연산자를 사용할수있다.
// OK in .cc files.
// Must be in a function, method or class in .h files.
using ::foo::bar;
*네임스페이스 별명은 .cc 파일 함수들 그리고 .h파일들의 메서들내부에서 사용할수있다.
// OK in .cc files.
// Must be in a function or method in .h files.
namespace fbz = ::foo::bar::baz;
Classes
클래스들은 C++에서 가장 기본적인 코드의 단위이다. 자연스럽게 우리는 클래스들을 확장적으로 사용한다.
이 섹션에서는 클래스를 작성하면서 해야할것과 하지 말아야 할 것들을 알아본다.
Default Constructors(기본생성자들)
당신이 정의한 클래스에 멤버 변수가 있고 어떤 다른 생성자들이 존재하지 않는다면 컴파일러가 기본 생성자를 자동적으로 생성해 줄 것이고 그 자동 생성자는 때에 따라서 재앙을 불러 일으킬 수 있다.
예를들어 처럼 헤더파일에 CMyClass를 정의하면
class CMyClass
{
private:
} ;
컴파일러는 나도 모르는사이 아래와 같이 기본생성자및 소멸자등을 자동적으로 만들어준다.
class CMyClass
{
public:
CMyClass() ; // 기본생성자
~CMyClass() ; // 소멸자
CMyClass( const CMyClass& c ) ; // 복사생성자
CMyClass& operator=( const CMyClass& c ) ; // 복사대입연산자
} ;
만약 멤버 변수에 동적으로 할당된 메모리나 스레드관련 동기화 오브젝트들이 있는경우 복사생성자또는 복사대입 연산자를 통해 조심스럽게 데이터를 복사하지 않으면 복사된 클래스의 데이터가 유효하지 않을 가능성이 크다.
정의 : 기본 생성자란 new 연산자로 클래스 객체를 어떠한 인자도 없이 생성할때 호출되어지는것이다.
또 기본 생성자는 new[]( 배열에 대해서) 를 호출할때도 호출되어진다.
장점 : 컴파일러가 알아서 멤버 변수들을 초기화하므로 디버깅이 훨씬 더 쉽지만 이상한 값들을 소유하고
있을 가능성이 있다.(Initializing structures by default, to hold "impossible" values, makes debugging much easier. )
단점 : 가끔은 더 많은 작업을 해야 할 때가 있다.(Extra work for you, the code writer)
결론 : 만약 클래스에 멤버 변수들이 있고 기본 생성자(인수가 전혀없는것)를 정의하지 않은 상태라면 당신은 기본생성자를 반드시 정의 해야한다.기본 생성자는 내부적인 상태를 모순없고 유효한 방법으로 객체를 초기화 하는 것이 바람직하다. 왜냐하면 당신이 어떤한 생성자들도 없고, 기본 생성자도 정의하지 않는다면 컴파일러가 그 기본 생성자를 알아서 생성 해 줄것이기 때문이다.(기본생성자외에 인수가 있는 다른 생성자를 정의 할 경우 기본 생성자를 자동적으로 만들지 않는다.) 근데 고맙게도 알아서 생성해준 기본 생성자가 때로는 재앙을 불러 일으킬수있다.
기존의 클래스로부터 상속하는경우 파생클래스에 어떠한 멤버 변수들도 추가하지 않았다면 파생클래스에 기본생성자를 꼭 정의할 필요는 없다. 위의 내용이 잘이해가 가질 안는 분은 Effective C++ 내용중 5, 12 부분을 읽어보길 바랍니다.
5.C++가 은근슬쩍 만들어 호출해 버리는 함수들에 촉각을세우다( 빈 클래스를 선언해도 생성자, 소멸자, 복사생성자, 복사대입연산자가 컴파일러에 의해 생성된다.)
12.객체의 모든 부분을 빠짐 없이 복사하자(해당 클래스의 데이터 멤버를 모두 복사하고, 이 클래스가 상속한 기본 클래스의 복사 함수도 꼬박꼬박 호출해 주자.)
Explicit Constructors (명시적 생성자들)
하나의 인수를 가진 생성자는 explicit 으로 선언하여라
정의 : 일반적으로 생성자가 하나의 인수를 가진다면 암시적변환이 발생할 수 있다.
예를들어 만약 생성자가 Foo::Foo(string name)로 선언되었다고 생각할대
Foo를 파라미터로 가진 함수에 문자열을 삽입하면 그 문자열은 암시적으로 Foo로 변환된다.
이런 암시적인 변환이 때론 편리하지만 당신이 바라지 않은 새로운 객체가 생성될때
알수없는 일들이 벌어질 수 있다.
생성자를 explicit으로 선언하는것은 암시적으로 호출 되어 변환되는것을 막는다.
장점 : 원치않는 암시적변환을 피한다.
단점 : None
결론 : 여러분은 매개별수 하나를 가진 생성자들은 모두 explicit으로 선언하는것이 좋다.
항상 단일매개변수 생성자들 앞에 explicit 키워드를 생활화 하자. : explicit Foo(string name) ;
단일매개변수 생성자인 복사 생성자는 위의 사항에 예외이다.
(Classes that are intended to be transparent wrappers around other classes are also exceptions)
또한 transparent wrappers around other classe 되기위해 고려되어진 클래스들도 또한 예외이다.
<-- 번역을 어떻게해야 좋을까여...
그런 예외들은 명확하게 주석을 써놔야 한다.
Copy Constructors(복사생성자)
클래스가 복사될 필요가 있는경우에만 복사 생성자를 사용해라.
대부분의 클래스는 복사될 필요가 없으며 만약 그렇다면 DISALLOW_COPY_AND_ASSIGN 를 사용할것.
정의 : 복사 생성자는 객체가 다른 새로운 객체로(특별히 값에의해 객체를 호출 할 때) 복사되어질때 사용되어진다.
장점 : 복사 생성자는 객체를 복사하기 쉽게 만들어준다. STL컨테이너� 모든 컨텐트타입들이 복사되어 들어가고 복사되어 나오도록 설계되어져있기때문에 클래스는 복사 가능하고 대입 가능해야 한다.
단점 : C++에서 객체의 암시적 복사는 버그와 성능문제를 일으킬수있는 잠재력이 크고 가독성도 떨어진다.
왜냐하면 객체가 참조와는 반대로 값에 의해 호출 되어지는 경우 암시적 복사가 일어나는 것을 추적 하기가 어렵게 되기 때문이다.
결론 : 대부분 클래스들은 복사될 필요가 없고 복사 생성자나 대입연사자가 필요없다.
그러나 운나쁘게 컴파일러는 복사 생성자나 대입 연산자를 정의, 선언 하지 않아도 컴파일러가 대신 복사생성자와 대입 연산자를 자동적으로 public 영역에 정의, 선언해준다. 복사생성자와 대입연산자가 필요 없는경우 확실히 금해야한다. 이런경우 private섹션에 정의만 하고 구현을 하지 않으면 해결된다.
그럼 클래스간 복사와 대입을 못하게 하며 만약 그럴경우 컴파 일러에러가 발생 한다.
우리는 private섹션에 이런 일을 해주는 매크로를 준비했다.
// A macro to disallow the copy constructor and operator= functions
// This should be used in the private: declarations for a class
#define DISALLOW_COPY_AND_ASSIGN(TypeName) \
TypeName(const TypeName&); \
void operator=(const TypeName&)
예로 class Foo: 에서는
class Foo {
public:
Foo(int f);
~Foo();
private:
DISALLOW_COPY_AND_ASSIGN(Foo);
};
처럼 하면 된다.
거의 모든경우에 여러분이 사용할 클래스에는 위에 설명한 DISALLOW_COPY_AND_ASSIGN 를 사용하게 될것이다. 만약 복사, 대입이 필요한 클래스가 인경우 그 클래스의 헤더 파일안에 왜 복사와 대입이 필요한지에 대해 문서화 해야 한다. 그리고 스스로 복사 대입연산자와 복사 생성자를 적절하게 정의해야한다.
operator=. (복사대입연산자)에서 자기대입에 대한 경우도 주의해서 구현해야만한다.
당신은 객체를 STL에 값으로 사용 하기 위해 복사 가능한 클래스가 필요할 수있다.
그러한 경우 당신은 STL컨테이너 안의 데이터타입을 포인터로 선언하는것이 훨씬더 좋다.
이런경우 예외및 안정성을 위해 std::tr1::shared_ptr을 사용하면 더욱 좋을것이다.
Structs vs. Classes (구조체를 사용할까 ? 클래스를 사용할까 ? )
데이터만 지닌(carry) 수동적 객체에 대해서는 struct를 사용하고 그밖에 모든것은 class를 사용해라.
struct 와 class키워드는 C++에서 거의 동일하게 행동한다.
다라서 여러분이 정의한 데이터 타입에 대해 적절한 키워드를 사용해야 한다.
데이터만 지닌(carry) 수동적 객체에 대해서는 struct를 사용되어져야 한다.
필드(데이터)의 접근, 수정(access/setting)은 함수 호출을 통한것 보다 필드(데이터)를 직접 접근하는것이 더 낮다.
즉...
struct MyStruct{
int var ;
}
struct MyStruct a ;
a.var = 1 ; // setting
int b = a.var ; // access
struct에서 제공할 만함 함수는 데이터 멤버들을 설정하기 위한 함수들만 사용해야한다.
예를들어 생성자, 소멸자, Initialize(), Reset(), Validate(). 등이다.
만약 더 많은 기능이 필요하다면 class가 훨씬 더 적절하다. 이럴땐 의심할 여지 없이 바로 class로 만들어라. 일관성있게 STL에서 사용하는 fuctors(함수객체)와 traits(특성)들은 class대신 struct를 사용할수 있다. 구조체와 클래스안의 멤버변수들은 다른 네이밍 규칙이 적용된다는것을 명심할것.
Inheritance(상속)
위임(또는 포함)은 종종 상속보다 좀 더 낮다.
상속을 사용할때 public으로 만들어라.
정의 : 서브(파생) 클래스가 기반 클래스로부터 상속할때 부모클래스에 정의된 모든 데이터와 메소드의 정의를 포함하게 된다. 실제로 상속은 C++에서 두 가지 주요 방법으로 사용되어지는 첫번째는 구현상속이고 두번째는 인터페이스 상속이다.
구현상속이라 함은 실제적인 코드가 하위 클래스에 의해 상속되어짐을 말하고 인터페이스 상속이라함은 함수(메소드) 이름만이 상속되어짐을 말한다.
장점 : 구현 상속은 마치 기존의 타입을 좀더 구체화(specializes)하는 처럼 기반클래스 코드의 재사용에 의해 코드 사이즈를 감소한다. 상속은 컴파일 타임 선언이기 때문에 여러분과 컴파일러는 기능을 이해하고 에러들을 찾는데 도움이 된다. 인터페이스 상속은 프로그램적으로 클래스가 특별한 API(메소드, 특히 순수가상함수들)을 노출(expose) 하도록 하기 위해 사용 되어진다. 따라서 컴파일러는 클래스가 API의 필수 메소드를 정의하지 않을경우 에러를 출력하게 된다.
class BaseClass
{
public:
virtual void method1() = NULL ;
} ;
class DerivedClass : public BaseClass
{
public:
// 기반클래스이 method1()을 정의, 선언하지 않음
} ;
DerivedClass d ; // Error 출력.
단점 : 구현상속에 대해서 서브 클래스에서 구현은 기반클래스와 서브클래스간의 모든 구현 코드들이 존재하기 때문에 구현을 이해하는데 좀더 까다롭게 될 수있다. 서브 클래스는 가상함수가 아닌 함수를 오버라이드 할 수 없다. 그래서 서브 클래스는 구현을 변경할 수 없다. 기반 클래스는 또한 기반클래스의 물리적 레이아웃을 설정하기위해 (so that specifies physical layout of the base class) 몇몇 데이터를 정의 할 수 있다.
[*물리적레이아웃이란 ? 멀까 ? ] 아는분
결론 : 모든 상속은 pulic이어야한다. 만약 여러분이 private 상속을 원한다면 여러분은 기반클래스의 인스던스를 상속대신 멤버 변수로서 포함해야한다. 구현상속을 남용하지 말것. 합성(포함)이 때에 따라서는 좀더 낮다.
상속은 "is-a"관계가 성립될때만 사용하도록하고 그렇치 않은경우 사용을 자제해야한다.
예를들어 Bar가 Foo를 상속할경우 Bar는 Foo의 종류이다("Bar is a kind of Foo")라고 말할 때 그 의미가 합리적이어야 한다.
만약 여러분의 클래스에 virtual함수가 하나라도 존재하면 소멸자를 virtual로 만들어야 한다.
서브 클래스로부터 접근되어질 필요가 있는 클래스의 멤버 함수로 protected의 사용을 제한하라.
데이터 멤버들이 있어야할 영역은 반드시 항상 private라는것을 잊지 말아라.
virtual 함수를 상속하여 재정의할때 파생클래스에도 명시적으로 함수 앞에 virtual를 사용하도록해라. 근본적이유 : 만약 virtual이 생략되어지면 코드를 읽을 때(특히 다른 엔지니어가) 그 함수가 가상인지 아닌지에 대한 의문점을 확인하려면 모든 상위 클래스들을 조사해야봐야 하기 때문에 무척 불편하게 된다.
Access Control(접근 제어)
모든 데이터 멤버들은 private 영역에 넣어라, 그리고 필요할때 접근자 함수(get)를 통해 데이터를 접근할수있도록 하여라.
보통 변수들은 foo_ 로 접근자 함수는 foo() 로 호출되어질 것이다. 또한 수정자 함수인 set_foo()도 제공 할수있다.
접근자와 수정자 정의는 헤더파일안에 인라인화되어진다.
See also Inheritance and Function Names.
Declaration Order(선언순서)
클래스 내부에 private전에 public 그리고 데이터 멤버전에 메소드순으로 선언하여라.
클래스 정의는 처음 public으로 시작해야한다. 그 후 protected: 부분과 private: 순으로 한다.
만약 각 섹션이 비어있다면 생략해라.
각 섹션(public:, protected:, private:)에서 선언들을 일반적으로 아래 순으로 해야만 한다.
*typedef 그리고 enum
*상수
*생성자
*소멸자
*메소드, 정적 메소드 포함
*데이터 멤버,(정적 데이터 멤버 포함)
.cc 파일에 연관된 메소드 정의들은 가능한 선언순으로 해야한다.
클래스정의파일안에 큰 메소드정의를 하지 말아라. 간단하고 짧은메소드만 인라인으로 정의되어져야한다
.
Write Short Functions (함수들을 짧게 작성해라)
작고 한가지 일만하는 함수가 더 좋다.
긴 함수들이 때대로 적절할때가 있다는것을 안다 그리고 함수의 길이때문에 하드의 제한을 받는경우는 없다.
만약 40라인을 초과하는 함수가있따면 프로그램 구조를 해치지 않는범위내에서 쪼갤 수 있는지 생각해라.
심지어 긴함수가 지금 완벽하게 적동하더라도 누군가 그것을 몇개월안에 수정하거나 추가할수있다.
이것이 찾기 힘든 버그를 만들 수 있다. 명심해라 함수는 짧고 단순하게 다른ㅅ람들이 읽고 수정하기 편하게 만들어야한다.
작업시 길고 복잡한 함수를 발견 할 수 있다. 그럼 함수를 더 작고 더 다루기 쉽게 쪼갤수있는지 고려해야한다.
Google-Specific Magic
우리는 C++코드를 좀더 견고하게 작성하기위한 다양한 트릭과 유틸리티들이 있고
지금까지 당신이 보왔던 코드와는 다른 C++코드를 다양한 방법으로 사용한다.
Smart Pointers(스마트포인터)
여러분은 일반적인 포인터를 할당하여 사용하려 할 때 scoped_ptr을 사용하는것이 좋다.
하지만 STL컨테이너들이 객체에 대한 포인터를 데이터 타입으로 사용하는 매우 특수한 경우에는 std::tr1::shared_ptr 을 사용해야한다. 이런경우에 auto_ptr을 사용하는것은 자살행위이다.
스마트포인터들은 할당된 포인터의 메모리를 스스로 관리할 수있는 객체들이다.
예를들어 scoped_ptr이 파괴되어질때 스마트포인터가 담고있는 포인터객체가 자동적으로 삭제된다. shared_ptr도 마찬가지이다. 그러나 shared_ptr은 레퍼런스 카운팅형식으로 메모리포인터를 관리한다.
레퍼런스 카운팅 형식이란 스마트포인터 객체끼리 관리되는 포인터의 참조 횟수를 기록해 두었다가
0 이되는 순간 더이상 사용을 안한다고 판단하여 관리되는 메모리를 삭제하는것을 말한다.
예를들어
MyClass* pmanaged_pointer ;
SmartPointer a(pmanaged_pointer); // reference count = 1 ;
SmartPointer b = a ; // reference count = 2 , b와 a가 관리되는 포인터가 동일하다.
// do somthing...
// a 소멸자 호출시 reference count = 1 로 감소.
// b 소멸자 호출시 reference count = 0 따라서... delete pmanaged_pointer ; 가 호출된다.
일반적으로 말해서, 우리는 명확한 객체 소유권을 가진 코드를 설계해야한다.
가장 명확한 객체 소유권은 포인터들을 사용하지 않고 객체를 직접적으로 필드나 지역 변수로서 사용함으로써 획득되어진다.
반면, 정의에 따르면 레퍼런스 카운트 포인터들은 어느누구에게나 소유되어질 수 있다.
이런 설계의 문제점은 순환레퍼런스 또는 객체가 절대로 삭제되어지지 않는 비이상적인 조건들이 생성되기 쉽다는 것이다. 그리고 매번 값들이 복사되어지거나 할당되어지는 원자적(기본적인) 연산자들을 수행하는데 느리다.
reference counted pointers 설계를 그리 추천하고싶지는 않지만, 때때로 한 문제를 풀기위한 가장 심플하고 우아한 방법이다,
Other C++ Features( 다른 C++ 특징들 )
sizeof
가능한 sizeof(type) 대신 sizeof(varname) 을사용해라.
왜냐하면 sizeof(varname)는 만약 변수의 타입이 변경되도 올바르게 그 값(size)을 리턴 시켜줄것이기 때문이다.sizeof(type) 는 몇몇 경우에는 괜찮치만 변수들의 타입이 변경된다면 의도하지않은 결과가 발생할 수 있기때문에(out of sync ) 일반적으로 피해야한다.
Struct data;
memset(&data, 0, sizeof(data)); // good
memset(&data, 0, sizeof(Struct)); // bad
만약 Struct 를 다름타입으로 바꾼다면 memset(&data, 0, sizeof(Struct)); 는 의도치 않은 결과가 발생할 수있다.
0 and NULL
정수형(integers)에대해서는 0, 실수(reals)는 0.0,포인터는 NULL,그리고 문자(chars)에 대해서는 '\0'을 사용해라.
정수형은 0을 실수에 대해서 0.0을 사용하라는것은 머 거진 다 아는사실인데..포인터에대해
0을 사용할것인지 NULL을 사용할 것인지는 논쟁의 여지가 좀 있다.
Bjarne Stroustrup는 그냥 0을 더 선호한다. 하지만 우리(구글)는 변수가 포인터처럼 보이는 NULL을 더 선호한다.
사실 몇몇 C++컴파일러에 예를들어 gcc 4.1.0 에서는 sizeof(NULL) 과 sizeof(0)이 동등하지 않은 특별한 상황에서 몇몇 유용한 경고들이 나타나도록 NULL의 특별한 정의들을 제공한다.
문자(chars)에대해서 '\0'를 사용하는것은 올바른것이고 또한 코드를 좀더 가독성있게 만든다.
Naming
File Names(파일이름)
파일명들은 모두 소문자여야하고 ( _ ) 나 ( - ) 를 포함 할 수 있다.
당신의 프로젝트에서 사용해야 하는 관례를 따를것.
허용될수있는 파일명 예제 :
my_useful_class.cc
my-useful-class.cc
myusefulclass.cc
C++파일은 .cc로 끝아야하고 헤더파일은 .h로 끝나야한다.
이미 /usr/include안에 있는 (예를들어 db.h) 파일명을 사용하지 말아라.
일반적으로 파일명은 매우 특징적이게 만들어야 한다. 예를들어 logs.h.보다 http_server_logs.h를 사용해라.
일반적으로 FooBar라는 클래스를 정의한 foo_bar.h 와 foo_bar.cc로 불리는 파일이 쌍으로 있다.
인라인 함수들은 .h파일안에 있어야만한다. 만약 인라인 함수들이 매우 짧다면 .h파일안에 직접 선언,정의해야한다. 그러나 인라인함수가 많은 코드를 포함한다면 그 인라인 함수는 다른 헤더파일인 -inl.h 에 선언,정의해야한다.
많은 인라인 코드를 가진 클래스경우 그 클래스는 3가지 파일을 가질수 있다.
url_table.h // The class declaration.
url_table.cc // The class definition.
url_table-inl.h // Inline functions that include lots of code.
See also the section -inl.h Files
Type Names(타입명)
타임명은 대문자로 시작하고 각각의 새로운 단어마다 (_) 없이 대문자를 가진다
MyExcitingClass, MyExcitingEnum
모든 타입들(클래스, 구조체, typedef , enum)의 이름들은 같은 네이밍 관례를 가진다.
타임명은 대문자로 시작하고 각각의 새로운 단어마다 (_) 없이 대문자를 가진다.
예를들어
// classes and structs
class UrlTable { ...
class UrlTableTester { ...
struct UrlTableProperties { ...
// typedefs
typedef hash_map PropertiesMap;
// enums
enum UrlTableErrors { ...
Variable Names (변수명)
변수명들은 각 단어사이마다 ( _ )를 붙이고 모두 소문자이다.
클래스 멤버 변수들은 끝에 ( _ ) 를 붙인다.
예를들어
my_exciting_local_variable, my_exciting_member_variable_.
string table_name; // OK - uses underscore.
string tablename; // OK - all lowercase.
string tableName; // Bad - mixed case.
Constant Names(상수명)
대소문자 혼합형태로 앞에 k로 시작한다. : kDaysInAWeek.
모든 컴파일타임 상수들은 지역적으로, 전역적으로 또는 클래스의 부분으로서든지 다른 변수들과 상당히 다른 네이밍 관례를 따른다. 단어의 첫번째 문자는 대문자이고 k로 시작되도록 한다.
const int kDaysInAWeek = 7;
Function Names(함수명)
일반적인 함수들은 대.소문자 혼합을 사용한다 ; 접근자와 수정자( set, get 계열)들은 변수의 이름과 일치시킨다.
MyExcitingFunction(),
MyExcitingMethod(),
my_exciting_member_variable(),
set_my_exciting_member_variable().
일반적인 함수
처음 대문자로 시작하고 각 단어 앞글자는 ( _ ) 없이 대문자를 갖는다
AddTableEntry()
DeleteUrl()
접근자와 수정자
접근자와 수정자들은 ( get 그리고 set 함수들) 얻고 설정하는 변수의 이름과 일치시켜야한다.
아래는 클래스 num_entries_ 변수의 접근자와 수정자들의 네이밍을 보여준다.
class MyClass {
public:
...
int num_entries() const { return num_entries_; }
void set_num_entries(int num_entries) { num_entries_ = num_entries; }
private:
int num_entries_;
};
당신은 또한 매우 짧게 인라인화된 함수들에 대해 소문자들을 사용할수있다.
Namespace Names(이름공간 이름)
네임스페이스 이름은 모두 소문자이고 프로젝트 이름에 기반하고 프로젝트 디렉토리 구조로도 가능하다 :
google_awesome_project
Enumerator Names(열거자명)
열거자들은 ( _ ) 와 함께 모두 대문자이어야한다. : MY_EXCITING_ENUM_VALUE
각각의 열거자들은 모두 대문자이어야한다. 열거자 명 UrlTableErrors는 타입이다. 그러크로 대,소문자를 함께 쓸수있다.
enum UrlTableErrors {
OK = 0,
ERROR_OUT_OF_MEMORY,
ERROR_MALFORMED_INPUT,
};
Comments(주석)
주석은 우리의 코드를 읽기 쉽도록 유지 하기위해 절대적으로 필요한 것이다.
아래 내용은 어떤 주석을 쓰는데 필요한 규칙들을 보여준다.
그러나 기억해라 : 주석이 매우 중요하긴하지만 최고의 코드는 자기 설명적(self-documenting) 이어야한다.(즉 코드만 봐도 무슨일을 하는건지 짐작이 가도록 작성하는것) 타입과 변수에 대한 적절한 이름들은 당신이 주석을 통해 설명해야만하는 부정확한 이름들을 사용하는것보다 훨씬 좋다.
주석을 쓸때 당신의 코드를 이해 할 필요가 있는 다음개발자를 위해 써라.
그 다음 개발자자는 아마 당신일 것이다.(즉 한창후에 자신이 그 코드와 주석을 보고 이해해야할 날이 온다는것)
Comment Style (주석 스타일 )
// or /* */ 를 사용해라
당신은 // or /* */ 를 사용할수있다; 그러나, //이 훨씬더 일반적이다.
Formatting
각자의 코딩 스타일과 포맷팅은 꽤 제멋데로이지만 모든 사람이 같은 스타일을 사용하는것이 좋다.
개개인별로 포맷팅 규칙의 모든면에 동의하지 않고 몇몇 규칙들만 따를수있지만 모든 프로젝트 개발자들은 모든사람들의 코드를 쉽게 읽고 이해할수 하기위해서 스타일 규칙을 따르는것이 중요하다.
Line Length (라인길이)
한라인에 최대 80글자를 넘지 않도록한다.
이 규칙은 좀 논쟁거리지만 기존의 코드들은 이미 이것을 따르고있고 우리는 일치성이 더 중요하다고 느낀다.
만약 주석라인이 80자보다 훨씬긴 URL이나 샘플 명령어들을 포함한다면 그 라인은 쉽게 자르기와 붙이기를 위해 80자보다 더 길수있다. 긴패스를 가진 #include 명령문은 80 컬럼들을 초과 할수있다. 이것이 필요한 상황을 피해라.
당신은 최대 길이를 초과하는 header guards 에 관해서는 걱정할 필요없다.
Spaces vs. Tabs
오로지 스페이스만 사용해라.
우리는 들여쓰기를위해 스페이스를 사용한다. 절대로 코드에 tab을 사용하지 말아라.
만약 tab키를 눌렀을때 스패이스들로 바뀌도록 에디터를 설정해야한다.
Function Declarations and Definitions(함수 정의와 선언)
웬만하면 함수명에 리턴타입과 파라미터(많치않은경우)를 쓰자.
즉 가장 보편적인것은 아래와 같다.
ReturnType ClassName::FunctionName(Type par_name1, Type par_name2) {
DoSomething();
...
}
하지만 리턴타입과 함수명, 그리고 파라미터를 한라인에 쓰기에 너무 많다면
다음처럼 할 수 있다.
ReturnType ClassName::ReallyLongFunctionName(Type par_name1,
Type par_name2,
Type par_name3) {
DoSomething();
...
}
또는 첫번째 파라미터가 너무 긴경우 아래처럼 할 수있다.
ReturnType LongClassName::ReallyReallyReallyLongFunctionName(
Type par_name1, // 4 space indent
Type par_name2,
Type par_name3) {
DoSomething(); // 2 space indent
...
}
주의할 몇몇 사항들은
● 리턴타입은 항상 함수와 같은라인에 있어야한다.
● ( 는 항상 함수와 같은 라인에 있어야한다
● 함수명과 ( 사이에 빈공간이 있으면 안된다.
● 파라미터와 ( ) 사이에 빈공간이 있으면 안된다.
● { 는 항상 마지막 파라미터의 끝에 있어야한다.
● } 는 마지막 라인에 있어야한다.
● ) 와 { 사이에 하나의 빈공간이 있어야한다.
● 모든 파라미터는 선언과 구현에 있어서 동일한 파라미터명을 가진 파라미터명을 반드시 갖아야한다.
● 모든 파라미터들은 가능한 정렬되어져야한다.
● 디폴트 두 빈공간으로 들여쓰기한다.
● 개행된(wrapped) 파라미터들은 4 빈공간으로 들여쓰기한다.
만약 const 함수인경우 const 키워드는 마지막 파라미터와 같은라인에 있어야만 한다.
// Everything in this function signature fits on a single line
ReturnType FunctionName(Type par) const {
...
}
// This function signature requires multiple lines, but
// the const keyword is on the line with the last parameter.
ReturnType ReallyLongFunctionName(Type par1,
Type par2) const {
...
}
만약 사용된지 않는 파라미터들이 있다면 파라미터 명에 /**/ 표시를 하자
// Always have named parameters in interfaces.
class Shape {
public:
virtual void Rotate(double radians) = 0;
}
// Always have named parameters in the declaration.
class Circle : public Shape {
public:
virtual void Rotate(double radians);
}
// Comment out unused named parameters in definitions.
void Circle::Rotate(double /*radians*/) {}
// Bad - if someone wants to implement later, it's not clear what the
// variable means.
void Circle::Rotate(double) {}
Function Calls(함수호출)
한라인에 함수를 호출하도록 하고 한라인이상인경우 인수를 ()로 정렬한다.
함수호출은 일반적으로 아래와 같은 형식으로 호출한다.
bool retval = DoSomething(argument1, argument2, argument3);
만약 인수들을 한라인에 모두 쓸수 없는경우 다중라인으로 개행해야만한다.
다중라인개행시 () 사이에 빈공간이 없어야하고 첫번재 인수를 기준으로 정렬되어져야 한다.
bool retval = DoSomething(averyveryveryverylongargument1,
argument2, argument3);
파라미터가 무지 많은 경우는 코드를 좀더 읽기 좋게 만들기위해 라인당 인수하나씩을 적도록 한다.
bool retval = DoSomething(argument1,
argument2,
argument3,
argument4);
만약 함수명이 너무 길어서 라인당 80자를 넘을수밖에 없는경우 모든 인수를 함수명 아래 라인에 적도록한다.
if (...) {
...
...
if (...) {
DoSomethingThatRequiresALongFunctionName(
very_long_argument1, // 4 space indent
argument2,
argument3,
argument4);
}
Conditionals(조건문)
() 안쪽에 빈공간이 없어야하며 else 키워드는 항상 다음(new line) 라인에 있어야한다.
기본적인 조건문장에 대해 2개의 스타일이 있다.
하나는 괄호와 조건문 사이에 빈공간을 포함하는 것이고 다른하나는 그렇치 않은 것이다.
가장 일반적인 형태는 괄호가 없는 것이다.
만약 당신이 이 조건문 형식에 맞게 기존의 소스파일을 수정할때 이 둘중에 한가지를 사용하고있다면 현재 사용했던것을 그대로 사용해라.
만약 새로운 코드를 쓴다면 프로젝트또는 다른파일들에서 사용한것과 같은 형식의 조건문 스타일 형식을 사용해라.
if (condition) { // 괄호 안쪽에 빈공간을 사용하지 말것.
... // 2 space indent.
} else { // else 키워드는 } 와 같은라인에 있을것.
...
}
만약 괄호안에 빈공간을 넣는것을 선호한다면 아래와 같이 할 수도있다.
if ( condition ) { // 괄호안에 빈공간을 넣는것 - 덜 선호됨.
... // 2 space indent.
} else { // else 키워드는 } 와 같은라인에 있을것.
...
}
괄호 사이(안쪽이 아니고 바깥쪽)에 빈공간이 반드시 있어야한다.
) 와 { 사이도한 하나의 빈공간이 있어야한다.
if(condition) // 나쁨 - if뒤에 빈공간을 빼먹었음
if (condition){ // 나쁨 - { 전에 빈공간을 빼먹었음
if(condition){ // 매우나쁨
if (condition) { // 좋음 - if와 {전후에 빈공간을 잘 넣었음
짧은 조검문에서는 가독성 향상을 위해서 한라인에 코드를 작성할수도있는데 이때는 라인이 짧거나 문장에 else가 들어가지 않는경우에만 사용해라.
if (x == kFoo) return new Foo();
if (x == kBar) return new Bar();
문장과 else를 한라인에 쓰면 안된다.
// Not allowed - IF statement on one line when there is an ELSE clause
if (x) DoThis();
else DoThat();
일반적으로 { } 는 단일 조건문장(if만 있는경우)에 대해서 요구되어지지 않지만 필요하면 사용할 수도있다.
if (condition)
DoSomething(); // 2 space indent.
if (condition) {
DoSomething(); // 2 space indent.
}
하지만 if-else 구조에서 {} 를 사용한다면 다른 하나도 반드시 사용해야한다.
// 안됨 - if문은 {} 를 사용했지만 else는 사용안했기 때문임.
if (condition) {
foo;
} else
bar;
// 안됨 - else문은 {} 를 사용했지만 if는 사용안했기 때문임.
if (condition)
foo;
else {
bar;
}
// if, else 둘다 잘 사용했음.
if (condition) {
foo;
} else {
bar;
}
Loops and Switch Statements (루프와 switch 문장)
switch 문장은 블럭을 위해 중괄호( {} ) 를 사용 한다.
비어있는 루프 몸체에는 {} 또는 conitnue 를 사용해야 한다.
switch 문자의 case 블럭은 {} 를 사용하고 안하고는 당신 맘이다.
만약 case 블럭에 {} 를 포함하고 싶다면 아래 보여지는 것처럼 해라.
만약 열거자값들이 아닌 조건자라면 switch문장은 항상 default case 를 가져야한다.
( 열거자값의 경우에 컴파일러는 만약 처리되지 않은 값이 있있으면 당신에게 경고할 것이다.)
만약 default case가 절대로 실행되지 않기를 바란다면 단순히 assert를 작성해라.
switch (var) {
case 0: { // 2 space indent
... // 4 space indent
break;
}
case 1: {
...
break;
}
default: {
assert(false);
}
}
비어있는 루프 몸체에는 {} 를 사용하던가 continue를 사용해야하며 싱글 세미클론이 있으면 안된다.
while (condition) {
// Repeat test until it returns false.
}
for (int i = 0; i < kSomeNumber; ++i) {} // Good - empty body.
while (condition) continue; // 좋음 - continue는 어떠한 로직도 없다는것을 가리킨다.
while (condition); // 나쁨 - 꼭 do/while문 처럼 보인다.
Pointer and Reference Expression!s (포인터 참조표현)
점(.)이나 화살표(->) 사이에 빈공간은 안된다.
포인터 연산자 사이에 빈공간이 있으면안된다.
다음은 올바르게 쓰여진 포인터와 참조표현식의 예이다.
x = *p;
p = &x;
x = r.y;
x = r->y;
멤버변수에 접근하려 할 때 점또는 화살표 주의에 빈공간이 있으면 안된다.
포인터 연산자들은 * 또는 & 후에 빈공간이 있으면 안된다.
포인터 변수와 인수를 선언할 때 변수이름 이나 타입 주변에 *를 놓으면 된다.
// 좋다, 빈공간이 앞에 있다.
char *c;
const string &str;
// 좋다. 빈공간이 다음에 있다.
char* c; // but remember to do "char* c, *d, *e, ...;"!
const string& str;
char * c; // 나쁘다 - * 양쪽사이에 빈공간이 있다.
const string & str; // 나쁘다 - & 양쪽사이에 빈공간이 있다.
Boolean Expression!s( 불리언 표현식)
여러분이 만약 참,거짓표현을 할 필요가 있는 곳에서는 표준라인길이 즉 한라인당 80자를 넘지 않도록 하고 만약 넘는다면 다음줄로 개행하도록한다.
예를들어 아래 AND연산자는 항상 라인의 끝에 있다.
if (this_one_thing > this_other_thing &&
a_third_thing == a_fourth_thing &&
yet_another & last_one) {
...
}
&& 로직 AND연산자의 둘다 라인의 끝인것을 유의해라.
불표현식에 보기 좋도록 ()를 삽입하는것은 맘대로해라
()들은 때때로 가독성을 증가시키는데 매우 도움을 준다.
if ((this_one_thing > this_other_thing) &&
(a_third_thing == a_fourth_thing) &&
(yet_another & last_one)) {
...
}
Return Values(리턴값)
return 표현식에 괄호(())로 둘러싸지 말아라.
return 값은 ()가 있어서는 안된다.
return x ; // not return(x)
Variable and Array Initialization(변수와 배열 초기화)
당신의 선택은 = 또는 () 로 초기화하는것이다.
아래샘플은 모두 올바르게 초기화 한것이다.
int x = 3;
int x(3);
string name("Some Name");
string name = "Some Name";
Preprocessor Directives(전처리 지시자)
전처리 지시자는 들여쓰지 않고 라인의 처음에 시작되어야한다.
심지어 전처리 지시자가 들여써진 코드의 몸체안에 있더라고 항상 라인의 처음부터 시작해야한다.
// 올커니 - 지시자들이 라인의 처음부터 시작한다.
if (lopsided_score) {
#if DISASTER_PENDING // Correct -- Starts at beginning of line
DropEverything();
#endif
BackToNormal();
}
// 나뻐나뻐 - 들여써진 지시자들이군..
if (lopsided_score) {
#if DISASTER_PENDING // Wrong! The "#if" should be at beginning of line
DropEverything();
#endif // Wrong! Do not indent "#endif"
BackToNormal();
}
Class Format(클래스형식)
클래스는 public, protected, private순으로하고 빈공간을 하나를 갖도록한다.
클래스선언의 기본적인 형식은
class MyClass : public OtherClass {
public: // Note the 1 space indent!
MyClass(); // Regular 2 space indent.
explicit MyClass(int var);
~MyClass() {}
void SomeFunction();
void SomeFunctionThatDoesNothing() {
}
void set_some_var(int var) { some_var_ = var; }
int some_var() const { return some_var_; }
private:
bool SomeInternalFunction();
int some_var_;
int some_other_var_;
DISALLOW_COPY_AND_ASSIGN(MyClass);
};
아래사항들을 기억해줘라..
*서브클래스이름은 기본 클래스 이름과 같은 라인에 있어야한다.(딴 80라인을 넘지 않는조건)
*public, proteted, private 키워드들은 한칸의 스페이스를 띠운다.
*첫번째 키워드를 제외하고 이들 키워드들은 빈라인이 다음에 써야한다. 이 규칙은 작은 클래스에서는 해도되고 안해도 된다.
*이 키워드들 뒤에 빈라인을 두지 말아라
*public 부분이 처음에 와야하고 그다음이 protected 마지막으로 private 부분이 와야한다.
*각 섹션에서의 선언순서 규칙은 다음과 같으면 Declaration Order를 볼것
Typedefs and Enums
Constants
Constructors
Destructor
Methods, including static methods
Data Members, including static data members
Initializer Lists(초기화 리스트)
생성자 초기화 리스트들은 한라인에 모두 쓰던가 아니면 들여쓰기(4칸) 하여 한라인 라인마다 쓸 수있다.
아래 초기화 리스트를 정의하기위한 2가지 형식을 보여준다.
// 한라인에 모두 있는경우..
MyClass::MyClass(int var) : some_var_(var), some_other_var_(var + 1) {}
// 다중라인이 필요한경우 들여쓰기(4칸)하고 초기화 라인에 클론 (,)을 붙이길 바란다.
MyClass::MyClass(int var)
: some_var_(var), // 4 칸 들여쓰기 클론(,)은 같은라인 끝에 있다.
some_other_var_(var + 1) { // 다음라인..
...
DoSomething();
...
}
Namespace Formatting(네임스페이스 형식)
네임스페이스안에 있는 내용들은 들여쓰기하지 않는다.
namespace {
void foo() { // 올커니 ,네임스페이스안에 들여쓰기가 안되어 있군..
...
}
} // namespac
namespace {
// 잘못�어. 네임스페이스가 있는데 들여쓰기 하고있잖어 .
void foo() {
...
}
} // namespace
Horizontal Whitespace ( 수평 빈공간 형식)
수평 빈공간의 사용은 위치에 따라 다르며 라인의 끝에 빈공간을 연속적으로 쓰면 안된다.
일반적으로..
void f(bool b) { // 열기 대괄호는 항상 전에 빈공간 하나가 있어야한다.
...
int i = 0; // 세미클론 전에는 빈공간이 있으면 안된다.
int x[] = { 0 }; // 배열을 초기화하기 위하여 대괄호를 사용할때 빈공간은
int x[] = {0}; // 있어도되고 없어도 되지만 한쪽이 있으면 있도록하고 없으면 없도록 통일해라
// 상속과 초기화 리스트에 있는 클론 주의에 빈공간이 있어야한다.
class Foo : public Bar {
public:
Foo(int b) : Bar(), baz_(b) {} // 빈 대괄호안에 어떠한 공간도 있지으면 안됨.
void Reset() { baz_ = 0; } // 인라인 함수 구현을 위해 , 대괄호와 구현사이에 빈공간을 두어라.
...
루프와 조건문사에서는...
if (b) { // 조건문과 루프를위한 키워드 다음에 빈공간이 필요하다.
} else { // else 주의에도 빈공간이 필요하다.
}
while (test) {} // 보통()사이에는 빈공간이 없어야한다.
switch (i) {
for (int i = 0; i < 5; ++i) {
switch ( i ) { // 루프나 조건문들 ()사이에 빈공간이 있을지도 모르지만
if ( test ) { // 그것은 좋치않고 빈공간이 없도록 일치시켜야한다.
for ( int i = 0; i < 5; ++i ) {
for ( ; i < 5 ; ++i) { // 루프들은 항상 세미클론 전,후에 빈공간 하나씩있다.
...
switch (i) {
case 1: // switch case의 : 전에 빈공간 있으면 안되고
...
case 2: break; // 클론 : 다음에 코드가 있는경우 빈공간을 써라.
연산자들을 사용할때..
x = 0; // 대입연산자들은 항상 주위에 빈공간을 쓸것.
++x; // 단항 연산자와 인수들사이에 빈공간 쓰지말것.
if (x && !y)
v = w * x + y / z; // 이항 연산자들은 보통 주위에 빈공간을 쓸것.
v = w*x + y/z; // 그러나 factors(나눗셈,곱셈) 주위에는 빈공간을 생략할 수 있음.
v = w * (x + z); // 괄호사이에는 빈공간쓰지 말것
템플레이트와 캐스트
vector x; // <> 사이에 빈공간쓰지 말것.
y = static_cast(x); //
//
vector *> x; // <> 안에 타입과 포인터간의 빈공간은 괜찮다.
// 그러나 웬만하면 없도록 하여라.
set > x; // 보통 C++에서 > > 사이에 빈공간이 필요하고
set< list > x; // 선택적으로 여러분은 < < 해도 된다.
Continue...
출처 : http://blog.daum.net/shuaihan/15449014