


[번역] 에이브로(Avro), 프로토콜 버퍼(Protocol Buffers) 그리고 스리프트(Thrift)의 스키마 변경(evolution)
이 내용은 소프트웨어 엔지니어이자 기업가인 마틴 클레프만(Martin Kleppmann)의 블로그에 있는(http://martin.kleppmann.com/2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html) 있는 내용이다. 이 내용의 번역은 마틴 클레프만의 동의를 얻어서 진행했다.
에이브로(Avro), 프로토콜 버퍼(Protocol Buffers) 그리고 스리프트(Thrift)의 스키마 변경(evolution).
자 여러분은 파일로 저장하거나 네트워크로 전송하려는 데이터를 가지고 있다. 그리고 변경(진화)의 여러 단계를 거치면서 스스로 찾아갈 수도 있다:
- 자바 직렬화(Java serialization), 루비 마샬(marshal)과 파이썬 픽클(pickle)같은 프로그래밍 언어가 지원하는 직렬화를 사용하거나, 자신의 포맷을 개발해서 사용할 수도 있다.
- 다음에, 단일 프로그래밍 언어에 종속된다는 것을 알게 될 것이고, 그래서, 더 넓게 지원하도록 JSON(XML) 같이 언어에 독립적인(language-agnostic) 포맷을 사용하도록 변경한다.
- 그다음으로, “JSON은 너무 장황(verbose)하고, 파싱이 느리다” 라고 판단하고, 부동 소수(floating point)와 정수(integers)를 구분할 수 없는 것에 실망하고, 유니코드 문자열뿐 아니라 바이너리 문자열도 필요하다고 생각한다. 그래서, JSON의 일종으로 바이너리(MessagePack, BSON, Universal Binary JSON, BJSON, Binary JSON Serialization) 포맷을 만든다.
- 또 다음으로, 사람들이 일관성 없는 타입을 사용해서, 객체에 여러 임의(random)의 필드를 넣고 있는 것을 발견하고, 스키마(schema)나 문서(documentation)에 대해서 매우 감사할 것이다. 아마도 당신 역시, 정적 타입 프로그래밍 언어를 사용하고 있고, 스키마에서 모델 클래스를 생성하길 원할 것이다. 그리고 바이너리 JSON은 계속해서 필드 이름을 저장하기에 실제로는 간결하지 않다는 것을 알게 될 것이다; 만약 스키마가 있다면, 객체 필드 이름을 저장하지 않아도 되고, 더 공간(bytes)을 절약할 수 있다.
만약, 4.의 단계를 고민한다면, 일반적으로 선택할 수 있는 옵션은 스리프트(Thrift), 프로토콜 버퍼(Protocol Buffers)와 에이브로(Avro)가 있다. 이 세 가지는 효율적이고, 스키마를 이용한 데이터의 언어에 독립적인(cross-language) 직렬화와 자바 진영(folks)을 위한 코드 생성도 제공한다.
이것들에 대한 비교는 이미(Protocol Buffers, Avro, Thrift & MessagePack, Thrift vs Protocol Bufffers vs JSON, Comparison of Protobuff, Thrift, Avro, etc) 확인할 수 있다. 하지만 많은 글이 일상적으로 보이지만, 중요한 세부내용을 간과하고 있다: 스키마를 변경하면, 어떻게 될까?
실제로 데이터는 항상 유동적이다. 완성된 스키마를 가지고 있다고 생각하는 순간, 누군가 예상치 않은 사례(use case)를 가지고 올 것이고, “단지 빠르게 필드를 추가”하길 원한다. 다행스럽게도, 스리프트, 프로토콜 버퍼 그리고 에이브로 모두 스키마 변경(schema evolution)를 지원한다: 스키마를 변경할 수 있는 동시에, 스키마의 다양한 버전에 대한 프로듀서(producers)와 컨슈머(consumers)를 사용할 수 있어서, 이전 버전의 스키마를 계속 사용할 수 있다. 이것으로, 호환성 걱정 없이, 서로 다른 시간에, 시스템의 각 컴포넌트를 독립적으로 갱신할 수 있게 해서, 매우 큰 시스템을 다룰 때, 매우 중요한 기능이다.
이것이 이 글의 주제이다. 실제로 프로토콜 버퍼, 에이브로 그리고 스리프트가 데이터를 데이터를 바이트로 인코딩하는 방법을 살펴본다. 이 내용은 개별 프레임웍이 스키마 변경을 처리하는 방법을 이해하는데 도움이 될 것이다. 이 프레임웍들이 만들어진 설계의 선택에 대해서 관심과 비교를 통해서 더 좋은 엔지니어가 될 수 있을 것이다.
예로, Person을 나타내는 작은 객체를 사용할 것이고, JSON으로 아래처럼 기술할 수 있다:
01 02 03 04 05 | { “userName”: “Martin”, “favouriteNumber”: 1337, “interests”: [“daydreaming”, “hacking”] } |
이 JSON 인코딩이 기준이 될 수 있다. 모든 공백을 지우면, 82바이트다.
프로토콜 버퍼
Person 객체에 대한 프로토콜 버퍼의 스키마는 아래와 같다:
01 02 03 04 05 | message Person { required string user_name = 1; optional int64 favourite_number = 2; repeated string interests = 3;} |
이 스키마로 데이터를 인코딩하면, 아래와 같이 33 바이트를 사용한다.
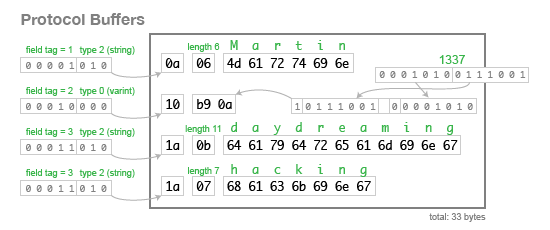
바이너리 형태가 어떻게 바이트 단위로 구성되는지 정확하게 살펴봐라. Person 레코드는 단지 필드의 연속이다. 각 필드는 태그 넘버(위의 스키마에서 1, 2, 3)를 지정하는 1 바이트로 시작하고, 다음으로 필드의 타입이다. 필드의 첫 바이트를 타입인 문자열로 지정한다면, 다음으로 문자열의 바이트 수와, UTF-8로 인코딩된 문자열이 따라온다. 첫 바이트를 정수로 지정한다면, 가변 길이로 인코딩된 수(값)가 나온다. 배열 타입은 없지만, 다중 값(multi-valued) 필드를 나타내기 위해서 태그 번호를 여러 번 사용할 수 있다.
이 인코딩 형태는 스키마 변화에 대해서 아래의 결과를 가진다:
- 선택적(optional), 필수적(required) 그리고 반복(repeated)되는 필드(태그 번호가 나타나는 횟수를 제외하고)의 인코딩 차이는 없다. 이것은 선택적에서 반복으로 변경할 수 있다는 것이고, 반대로 변경해도 같다(파서가 예상한 선택적 필드에, 한 레코드에 같은 태그 번호가 여러 번 보이는 경우, 마지막 값을 제외하고 모두 삭제한다.)는 것이다. 필수적 필드는 추가로 유효성 검사를 한다. 그래서 스키마를 바꾼다면, 런타임 에러(메시지를 보내는 사람은 선택적이라고 생각했지만, 받는 쪽이 필수라고 생각하는)의 위험이 있다.
- 빈 값의 선택적 필드 또는 0 값이 반복되는 필드는 인코딩된 데이터에 전혀 나타나지 않는다-다만 태그 번호만 나온다. 따라서 스키마에서 이런 종류의 필드는 삭제하는 것이 안전하다. 하지만 아직도 삭제한 필드의 태그를 사용해서 저장된 데이터가 있을 수 있기에, 앞으로는 다른 필드에서 태그 번호를 재사용하면 안 된다.
- 태그 번호를 제공할 수 있다면, 레코드에 필드를 추가할 수 있다. 프로토콜 버퍼 파서가 스키마에 정의되지 않은 태그 번호를 만나면, 그 필드가 호출됐는지 알 수가 없다. 하지만 필드의 첫 바이트에 3-bit 타입코드가 포함되어 있어서, 대략 어떤 타입인지 알고 있다. 이것은 파서가 정확히 필드를 해석할 순 없지만, 이것으로 레코드에서 다음 필드를 찾기 위해, 몇 개의 바이트를 생략해야 하는지 알 수 있다.
- 직렬화된 바이너리에 필드 이름이 없기에, 필드 이름을 바꿀 수 있지만, 태그 번호는 바꿀 수 없다.
개별 필드를 나타내기 위해서 태그 번호를 사용하는 방식은 간단하고 효과적이다. 하지만 이 방식이 유일하지 않다는 것은 금방 알 수 있을 것이다.
에이브로
에이브로 스키마는 2가지 방법으로 사용할 수 있고, 한 가지 방법은 JSON 포맷을 사용하는 것이고:
01 02 03 04 05 06 07 08 09 | { “type”: “record”, “name”: “Person”, “fields”: [ {“name”: “userName”, “type”: “string”}, {“name”: “favouriteNumber”, “type”: [“null”, “long”]}, {“name”: “interests”, “type”: {“type”: “array”, “items”: “string”}} ]} |
다른 방법은 IDL을 사용하는 것이다:
01 02 03 04 05 | record Person { string userName; union { null, long } favouriteNumber; array<string> interests;} |
스키마에 태그 번호가 없는 것을 확인해라! 그럼 어떻게 동작할까?
아래는 32바이트로 인코딩(http://avro.apache.org/docs/current/spec.html)된 같은 예제 데이터다.
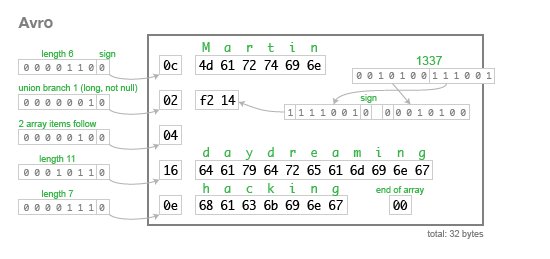
문자열 앞은 길이(length)이고 다음으로 UTF-8 바이트지만, 바이트스트림(bytestream)은 그것이 문자열이라고 알려주지 않는다. 이것(바이너리 데이터)은 단지 가변 길이 정수가 될 수 있지만, 완전히 다를 수 있다. 이 바이너리 데이터를 파싱할 수 있는 유일한 방법은 스키마와 같이 읽는 것이고, 스키마는 다음에 나오는 타입이 무엇인지 알려준다.
데이터의 작성자(writer)가 사용한 스키마의 정확히 같은 버전이 필요하다. 다른 스키마를 가지고 있다면, 파서는 바이너리 데이터의 헤드(head)나 테일(tail)을 만들 수 없게 될 것이다.
그런데 에이브로는 어떻게 스키마 변화를 지원할까? 비록 작성자의 스키마로 작성된 데이터와 정확한 스키마를 알 필요가 있지만, 컨슈머(consumer)가 기대하는(구독자(reader)의 스키마) 스키마가 같아야 한다는 것은 아니다. 실제로, 에이브로 파서에 다른 두 개의 스키마를 제공할 수 있고, 파서는 작성자 스키마를 구독자 스키마로 변환하기 위해서 해결 규칙(resolution rules)을 사용한다.
이것은 스키마 변화에 대해 몇 가지 흥미로운 결과를 가지게 한다:
- 에이브로 인코딩은 어떤 필드가 다음인지 알려주는 지시자(indicator)가 없다: 단지, 스키마에 나타나는 차례대로 인코딩한다. 파서는 필드가 생략되었다는 것을 알 방법이 없기에, 에이브로에는 선택적인 필드가 없다. 대신, 값을 제외하길 원한다면, 위에서 유니온(union { null, long })과 같은 타입을 사용할 수 있다. 유니온 타입을 사용하기 위해서, 파서에게 1바이트로 인코딩해서 알려준다. null 타입(간단히 0바이트로 인코딩됨)으로 유니온을 만들어서, 필드를 선택적으로 만들 수 있다.
- 유니온 타입은 강력하지만, 변경 시에는 주의해야 한다. 유니온에 한 타입을 추가하려면, 우선, 모든 구독자에 새로운 스키마 업데이트가 필요하고, 변경 내용을 알게 된다. 모든 구독자(readers)가 업데이트되면, 작성자(writers)는 생성하는 레코드에 새로운 타입을 추가할 수 있다.
- 원하는 대로, 레코드에서 필드를 재정렬할 수 있다. 비록 필드는 정의된 순서로 인코딩되지만, 파서는 구독자와 작성자 스키마에서 이름으로 필드를 찾을 수 있고, 이것이 에이브로에서 태그 번호가 필요없는 이유이다.
- 이름으로 필드를 찾을 수 있기에, 필드의 이름을 변경하는 것이 까다롭다. 새로운 필드 이름을 사용하기 위해서, 기존 이름의 별칭(구독자의 스키마에서 별칭을 이름 매칭에 사용한 이래)으로 유지하는 동안, 데이터의 모든 구독자는 먼저 업데이트가 필요하다. 다음에, 새로운 필드를 사용하기 위해서 작성자의 스키마를 업데이트할 수 있다.
- 또, 기본 값(예로 null, 필드의 타입이 union이고 기본값이 null이면)을 정해서, 레코드에 필드를 추가할 수 있다. 구독자가 새로운 스키마로 기존 스키마(필드가 부족한)로 작성된 레코드를 파싱할 때, 대신 기본값으로 채울 수 있기에, 기본값이 필요하다.
- 반대로, 레코드에서 기존에 기본값을 가지고 있는 필드를 삭제할 수 있다(이것이, 가능한 모든 필드에 기본값을 제공하는 것이 유익하다는 이유다). 구독자가 기존 스키마로 새로운 스키마로 작성된 레코드를 파싱할 때, 기본값으로 돌릴 수 있다.
이것은 작성된 특정 레코드의 정확한 스키마를 알아야 하는 문제를 남긴다. 그래서 가장 좋은 해결책은 데이터가 사용되고 있는 상황(context)에 따르는 것이다.
- 일반적으로, 하둡(Hadoop)에서는 모두 같은 스키마로 인코딩된, 수백만의 레코드를 유지하는 파일이 많이 있다. 객체 컨테이너 파일(Object container files)이 이 파일들을 처리한다: 단지 파일의 시작 부분에서 스키마를 가지고 있고, 나머지 부분에 스키마로 디코딩할 수 있다.
- RPC(Remote Procedure Call)에서, 요청과 응답에서 매번 스키마를 보내는 것은 너무 오버헤드가 클 것이다. 하지만 RPC 프레임웍이 오래 유지하는(long-lived) 연결을 사용한다면, 연결 시점에서 한번 스키마를 협상(주고받으면서 확인)할 수 있고, 많은 요청의 오버헤드 비용을 상쇄할 수 있다.
- 데이터베이스에 하나씩 레코드를 저장한다면, 다른 시간대에 작성된 여러 스키마 버전으로 저장할 수 있고, 그래서 스키마 버전의 각 레코드에 주석이 필요하다. 스키마 자체를 저장하는 것이 너무 오버 헤드가 큰 경우, 스키마 해시나 차례대로 스키마 버전 번호를 사용할 수 있다. 이때는, 특정 버전 번호에 대해서, 정확한 스키마 버전을 찾을 수 있는 스키마 레지스트리(schema registry)가 필요하다.
이것을 고려하는 한 방법으로: 프로토콜 버퍼에서는, 레코드의 모든 필드를 태그하고, 에이브로에서는, 전체 레코드, 파일 또는 네트워크 연결을 스키마 버전으로 태그한다.
언뜻 보기에는, 스키마 배포에 부가적인 노력이 필요하기에, 에이브로 방식이 더 복잡하게 보일 수 있다. 하지만, 에이브로 방식이 가지고 있는 몇 가지 의미있는 장점에 대해서 생각해 보자:
- 객체 컨테이너 파일의 스스로-기술하는(self-describing) 것은 매우 좋다: 파일에 내장된 작성자 스키마는 모든 필드의 이름과 타입을 포함하고 있고, 심지어 문서 문자열(스키마의 작성자(author)가 귀찮아하는 일부 일들)도 포함하고 있다. 이것이 피그(Pig)와 같은 대화형(interactive) 툴에 직접 해당 파일을 읽거나, 어떤 구성 없이도 바로 작업(Works™)할 수 있게 한다.
- 에이브로 스키마는 JSON으로, 자신의 메타데이터를 파일에 추가(예로 어플리케이션 수준에서 필드에 대한 의미를 기술하는)할 수 있다.
- 스키마 레지스트리는 아마도 문서(documentation)를 제공하고, 데이터를 찾거나 재사용하는 것을 도와줄 때에 유익할 것이다. 그리고 스키마 없이는 에이브로 데이터를 파싱할 수 없기에, 스키마 레지스트리는 최신으로 보장되어 있다. 물론, 프로토콜 버퍼 스키마 레지스트리도 역시 설정할 수 있지만, 필요한 기능이 없으므로, 단지 최선을 다했다는 근거만 될 것이다.
스리프트
스리프트는 데이터 직렬화 라이브러리 뿐 아니라, 전체가 RPC 프레임워크라서, 에이브로나 프로토콜 버퍼보다 큰 프로젝트이다. 스리프트는 또 다른 방식을 가지고 있다: 에이브로나 프로토콜 버퍼는 단일 바이너리 인코딩을 표준으로 하지만, 스리프트는 다양한 직렬화 포맷(“프로토콜”이라고 하는)을 포함(embraces)한다.
사실, 스리프트는 두 가지(1, 2) JSON 인코딩 방식이 있으며, 최소한 3가지의 바이너리 인코딩 방식을 가지고 있다(하지만, 바이너리 인코딩의 하나인 DenseProtocol은 오직 C++ 구현만 지원하고 있다: 언어 중립적인(cross-language) 직렬화에 관심이 있기에, 다른 두 가지에 중점을 둘 것이다).
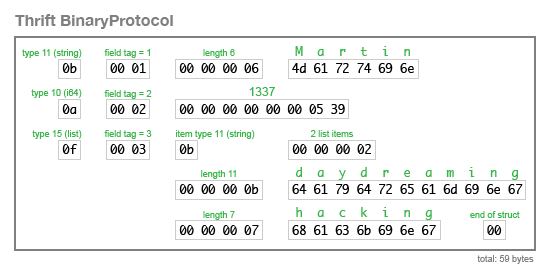
모든 인코딩은 스리프트 IDL에서 정의된 같은 스키마를 공유한다:
01 02 03 04 05 | struct Person { 1: string userName, 2: optional i64 favouriteNumber, 3: list<string> interests} |
바이너리 프로토콜(BinaryProtocol) 인코딩은 매우 간단하지만, 상당히 비효율적(위의 예제 레코드를 인코딩하기 위해서 59바이트를 사용)이다:
컴팩트 프로토콜(CompactProtocol) 인코딩은 의미상 같지만, 크기를 34바이트로 줄이기 위해서 가변-길이 정수와 비트 패킹을 사용한다:
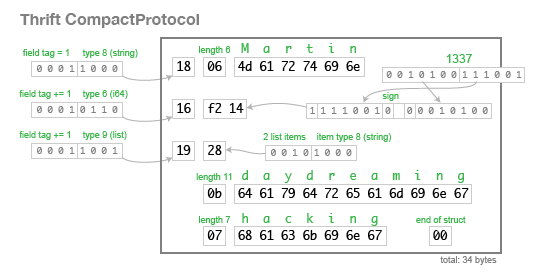
보다시피, 스리프트의 스키마 변화에 대한 대처 방식은 프로토콜 버퍼와 같다: 각 필드는 IDL에 수동으로 태그를 할당하고, 태그와 필드 타입은 인코딩된 바이너리에 저장하고, 이것으로 파서가 알지 못하는 필드는 생략할 수 있도록 한다. 스리프트는 프로토콜 버퍼의 반복 필드 방식보다 명시적인 리스트 타입을 정의하지만, 이 두 개는 매우 유사하다.
사상적인 관점에서, 위 라이브러리들은 매우 다른 관점을 가지고 있다. 스리프트는 전체가 통합된 RPC 프레임웍이고, 많은 선택(다양한 언어를 지원)을 주는 “한 상점에서 여러 가지 상품을 파는(one-stop shop)” 형태를 선호한다. 반면에, 프로토콜 버퍼와 에이브로는 “한 가지 일을 더 잘하는” 형태를 더 선호하는 것으로 보인다.
원 글에 있는 답글 중에 하나로 “에이브로는 스리프트보다는 작지만 RPC 프레임웍이고, IPC도 지원한다”고 한다.
'Server > Thrift' 카테고리의 다른 글
| [펌] 직렬화 방법, Facebook의 Thrift와 Protocol Buffers의 비교. (0) | 2014.12.26 |
|---|---|
| Thrift vs Protocol Buffers 비교문 요점 정리 (0) | 2014.12.26 |