

[펌] Audio Clip
원문 - http://docs.unity3d.com/Manual/class-AudioClip.html
음향 쪽 볼일이 생겨 번역해서 적어놓습니다. 오역이 있을 수 있습니다. T_T
Audio Clip
Audio Clip은 Audio Source가 사용하는 음향 정보를 포함하고 있습니다. 유니티는 모노널, 스테레오와 다 채널 음향 자산(최대 8채널)을 지원합니다. 유니티가 사용할 수 있는 음향 파일 포맷은 .aif, .wav, .mp3와 .ogg이며 .xm, .mod, .it와 .s3m 포맷인 tracker module도 사용할 수 있습니다. tracker module 자산은 자산 추출 조사기(asset import inspector) 탭에서 파형 미리 보기가 불가능하지만 다른 음향 자산과 같은 방식으로 동작합니다.
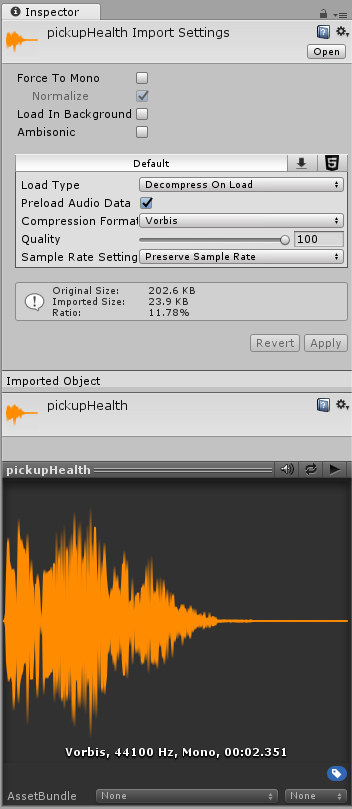
Audio Clip 조사기
속성
Load type(불러오기 방식)
실행 시 유니티가 음향 자산을 불러오는 데 사용하는 방법.
Decompress on load(불러올 때 압축해제)
음향 파일이 불러오는 즉시 압축이 해제됩니다. 즉시 압축 해제로 생기는 성능 부담(overhead)을 피하려면 이 옵션은 압축된 작은 소리에 사용하세요. Vorbis로 인코딩된 소리를 불러와 압축을 해제하면 압축 때보다 대략 열 배 정도의 메모리를 더 사용하게 되니 (ADPCM 인코딩의 경우는 대략 3.5배) 이 옵션을 큰 파일에는 사용하지 마세요.
Compressed in memory(메모리에 압축)
메모리에 소리를 압축된 상태로 유지하며 재생 중에 압축 해제합니다. 이 설정은 약간의 성능 부담(특히 Ogg/Vorbis 압축 파일)이 생기므로 불러와서 압축 해제시 메모리의 양(파일 크기)이 엄청나게 큰 파일에만 사용하세요. 압축 해제는 합성 스레드에서 일어나며, 분석기 창의 음향 구획의 "DSP CPU" 항목에서 확인할 수 있습니다.
Streaming(바로 재생)
소리를 바로 디코딩합니다. 이 방식은 압축된 데이터를 재생하는 데 필요한 최소한의 메모리만을 사용하기 때문에 디스크 읽기가 증가하고 바로 디코딩합니다. 각각의 스레드에서 일어나는 압축해제는 분석기 창의 음향 구획의 "Streaming CPU" 항목에서 확인할 수 있습니다.
Compression Format(압축 포맷)
실행 시 소리에 사용될 특정 포맷. 이 설정이 사용 가능한지는 현재 선택된 빌드 타겟에 따릅니다.
PCM
이 설정은 파일 크기가 클수록 더 높은 품질을 제공합니다. 아주 짧은 효과음에 최적입니다.
ADPCM
이 포맷은 많은 양의 잡음을 포함한 소리와 발자국, 충격, 무기 같은 자주 재생해야 하는 소리에 효과적입니다. 압축 비율은 PCM 대비 3.5배 더 작지만, CPU 사용량은 MP3/Vorbis보다 더 낮아서 앞서 말한 종류의 소리에 선택 시 선호됩니다.
Vorbis/MP3
파일 압축 결과가 작지만, 음질은 PCM 음향과 비교해서 다소 떨어집니다. 압축량은 음질 조정 단추를 움직여서 조정할 수 있습니다. 이 포맷은 중간 길이의 효과음과 음악에 최적입니다.
HEVAG
PS Vita에서 사용하는 고유 포맷입니다. 사양은 ADPCM과 매우 유사합니다.
Sample Rate Setting(추출률 설정)
Preserve Sample Rate(추출률 유지)
이 설정은 추출률을 수정하지 않은 채로 유지합니다. (기본)
Optimize Sample Rate(추출률 최적화)
이 설정은 추출률을 분석된 가장 높은 주파수 성분에 따라서 자동으로 최적화합니다.
Override Sample Rate(추출률 덮어쓰기)
이 설정은 수동으로 추출률을 덮어쓸 수 있게 합니다. 주파수 성분을 무시하려 할 때 효과적입니다.
Force To Mono(강제 모노널)
설정을 켜면, 음향 클립은 단 채널 소리로 내림 합성됩니다. 내림 합성한 신호는 최고치로 평균화되는데 이는 신호의 내림 합성 진행 결과물이 보통 원본보다 소리가 더 작기 때문이며, 이로 인해 최고치로 평균화된 신호는 향후 AudioSource의 음량 설정을 통한 조정을 위해 상단 부분(headroom)을 더 줍니다.
Load In Background(뒤에서 불러오기)
설정을 켜면, 음향 클립은 주 스레드를 멎게(stall) 하지 않기 위해 뒤에서 불립니다. 이 설정은 장면 재생이 시작될 때 모든 음향 클립을 불러와 완료하는 표준 유니티 행동을 확실히 하기 위해 기본으로 꺼져 있습니다. 뒤에서 아직 불러오고 있는 음향 클립에 대한 재생 요청은 클립 불러오기가 완료될 때까지 지연된다는 것을 알아두세요. 불러오기 상태는 AudioClip.loadState 속성으로 질의할 수 있습니다.
Preload Audio Data(음향 자료 미리 불러오기)
설정을 켜면, 음향 클립이 장면이 불릴 때 미리 불리게 됩니다. 이 설정은 장면 재생이 시작될 때 모든 음향 클립을 불러와 완료하는 표준 유니티 행동을 나타내기 위해 기본으로 켜져 있습니다. 이 설정이 지정되어 있지 않으면, 음향 데이터는 AudioSource.Play()/AudioSource.PlayOneShot()을 처음 사용할 때나 AudioSource.LoadAudioData()를 통해 불릴 수 있으며 AudioSource.UnloadAudioData()를 통해 불러오기를 다시 되돌릴 수 있습니다.
Quality(음질)
압축 포맷 클립의 압축량을 결정합니다. PCM/ADPCM/HEAVG 포맷은 적용되지 않습니다. 파일 크기 통계는 조사기에서 볼 수 있습니다. 이 값을 조정하는 좋은 방법은 조정 단추를 배포 사양에 맞춰 파일 크기는 작게 유지하며 재생 시 '충분히 좋은' 위치에 끌어다 놓는 것입니다. (당연한 소리 아닌가?!) 원본 크기는 원본 파일과 연관이 있는 점을 알아두세요. 파일이 MP3이고 압축 포맷이 PCM으로 설정되어 있으면, (즉 무압축) 파일은 이제 무압축으로 담기고 원본 MP3보다 공간을 더 사용하기 때문에 결과 비율은 100%보다 클 것입니다.
미리 보기 창
미리 보기 창은 세 가지 아이콘을 갖고 있습니다.
![]() 선택된 클립을 자동으로 바로 재생하려 할 때.
선택된 클립을 자동으로 바로 재생하려 할 때.
![]() 클립을 연속으로 반복해서 재생하려 할 때.
클립을 연속으로 반복해서 재생하려 할 때.
![]() 클립을 재생합니다.
클립을 재생합니다.
음향 자산 가져오기
유니티는 넓은 범위의 원본 파일 포맷을 읽을 수 있습니다. 파일을 가져오게 되면 빌드 타겟과 소리 종류에 맞춰 포맷을 변환합니다. 이는 조사기안에 있는 압축 포맷 설정을 통해 선택할 수 있습니다.
보통 PCM과 Vorbis/MP3 포맷은 원본에 가능한 근접하게 소리를 유지할 수 있어 주로 사용됩니다. PCM은 소리가 압축되지 않고 메모리에서 바로 읽을 수 있으므로 CPU에 요구하는 사양이 아주 적습니다. Vorbis/MP3은 음질 조정 단추를 조정해서 듣기 어려운 정보를 무시할 수 있습니다.
ADPCM은 무 압축된 PCM 설정보다 약단 더 CPU를 사용하므로 CPU와 메모리 사용량 사이를 절충하지만, Vorbis나 MP3 압축으로 얻을 수 있는 압축보다 보통 약 3배 정도 좋지 않은 압축비 3.5를 일정하게 얻게 됩니다. 더욱이 ADPCM은 (PCM과 같이) 자동 최적화나 소리의 주파수 성분과 적당한 품질 저하를 사용한 수동 추출률 지정을 통해 꽉 찬 소리 자산의 크기를 좀 더 줄일 수 있습니다.
module 파일(.mod, .it, .s3m, .xm)은 극히 작은 크기로 고품질을 낼 수 있습니다. 특별히 원하지 않는 이상 module 파일을 사용할 때는 불러오기 방식을 Compressed In Memory으로 설정했는지 확인하세요. 왜냐하면, Decompress On Load로 설정되어 있으면 전체 곡이 압축해제 되기 때문입니다. 이는 이런 종류의 클립 또한 GetData/SetData 사용을 허용하는 유니티 5.0의 새로운 동작 방식이지만 tracker module을 사용하는 일반적이고 기본적인 경우에는 Compressed In Memory으로 설정해야 합니다.
일반적인 경험에 따르면 압축된 음향(이나 module)은 배경음이나 대화 같은 긴 파일에 최적이며, PCM과 ADPCM은 부드러운 신호에서 누가 봐도 심한 ADPCM의 아티팩트 같은 약간의 잡음을 포함한 효과음에 최적입니다. 압축 조정 단추를 사용해서 압축량을 조정할 수 있습니다. 높은 압축에서 시작해 음질 저하를 인지할 수 있는 지점까지 서서히 설정을 내립니다. 그다음 음질 저하가 사라지는 걸 알 수 있을 때까지 약간씩 올립니다.
플랫폼별 특정 세부내용
iOS/Android
휴대용 플랫폼에서는 명시적으로 MP3를 선택하지 않으면 Vorbis 코덱으로 인코딩됩니다.
'Unity3D > Tips' 카테고리의 다른 글
| [펌] 에디터에서 게임 플레이를 할 때 저장되지 않은 Assets 저장하기 (0) | 2016.09.30 |
|---|---|
| Latest Optimization Initiative for Unity Games (0) | 2016.09.18 |
| [펌] 유니티 프로그래머가 알아야 할 최적화 스크립트 코드 작성법 (0) | 2016.08.30 |
| [펌] 유니티 최적화 : 아트 리소스 최적화 기법들 (0) | 2016.08.30 |
| [링크] APK용량 줄이기, 이미지 압축 (0) | 2016.08.09 |





 Dvornik-Unity-Distortion.zip
Dvornik-Unity-Distortion.zip










































